Partially AI-modified / AI transparency: This publication is AI-assisted and human-reviewed. Constantin Korte assumes editorial responsibility. See AI Transparency.
Good agentic engineering is not a prompt trick. It is a workspace contract: scope, tools, backlog, pipeline, tests, browser proof, and one deployable source of truth.
When people hear “agentic AI”, they often imagine a smarter chat window. That is too small. In real engineering work, the agent sits inside a workspace: a Git repository with source code, scripts, documentation, and sometimes controlled access to tools like a terminal, APIs, a browser testing tool, or a deployment pipeline.
By agentic engineering I mean engineering work where an AI agent can answer, inspect, change, run, verify, and report inside a bounded workspace.
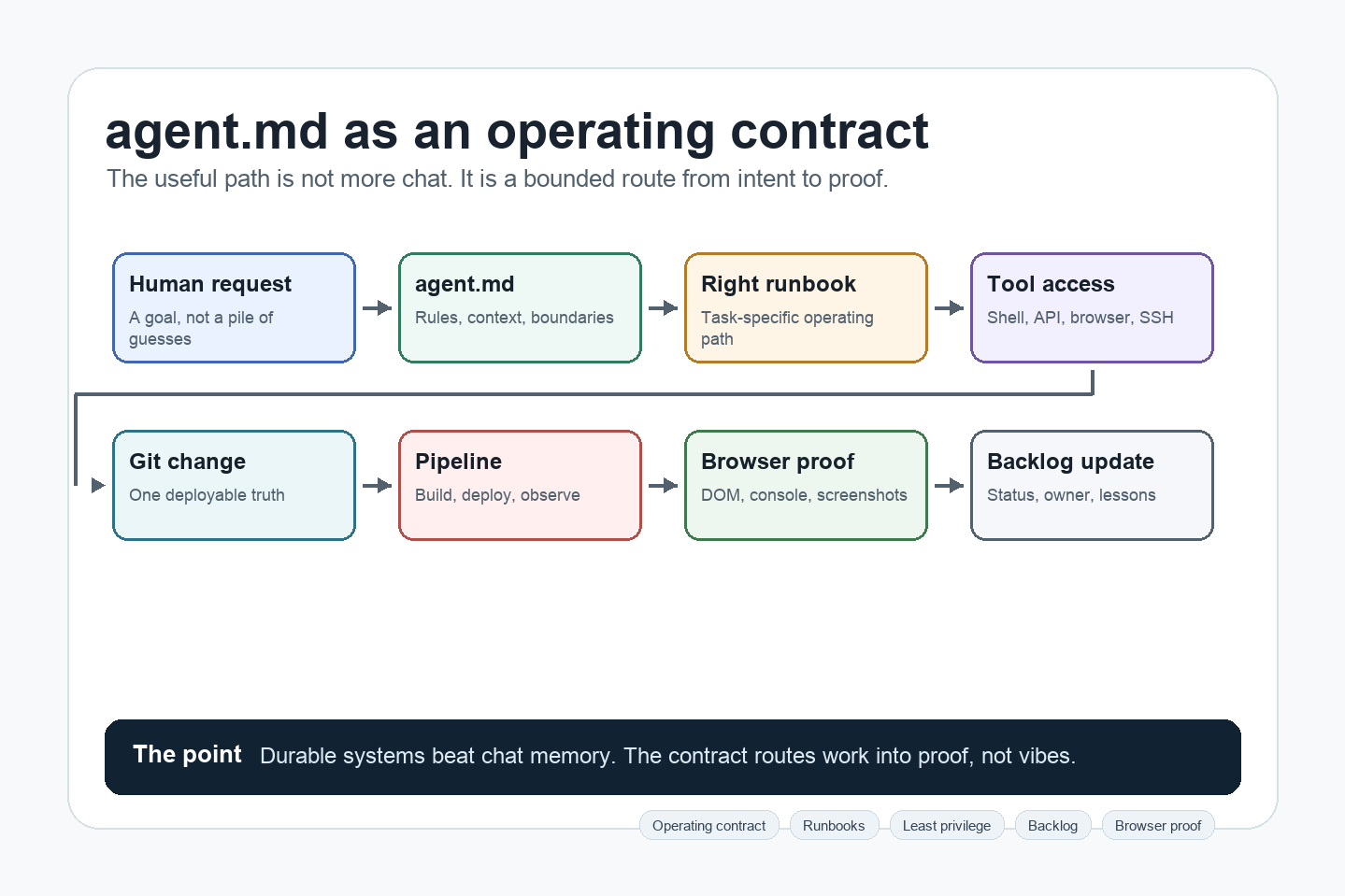
AGENTS.md is an open Markdown convention for guiding coding agents. The easiest way to think about it is this: it is a README for the agent. A README helps a human understand the project. An AGENTS.md or agent.md helps the agent understand how it is allowed to work.
In my projects, that file does more than list commands. It explains where the truth lives, how work enters the backlog, which runbooks matter, what systems may be touched, what is off-limits, and what proof is required before anything is called done.
That is the important move. Good agentic work is not primarily about one clever prompt. It is about giving the agent a real operating model, then forcing the work to pass through evidence: Git changes, pipeline runs, browser checks, logs, tests, and backlog updates.
So yes, many teams now have an AGENTS.md or agent.md. The difference is how seriously it is treated. For me, it is not a preferences file. It is the operating contract for the work.
The prompt still matters, but the working environment matters more.
The real problem
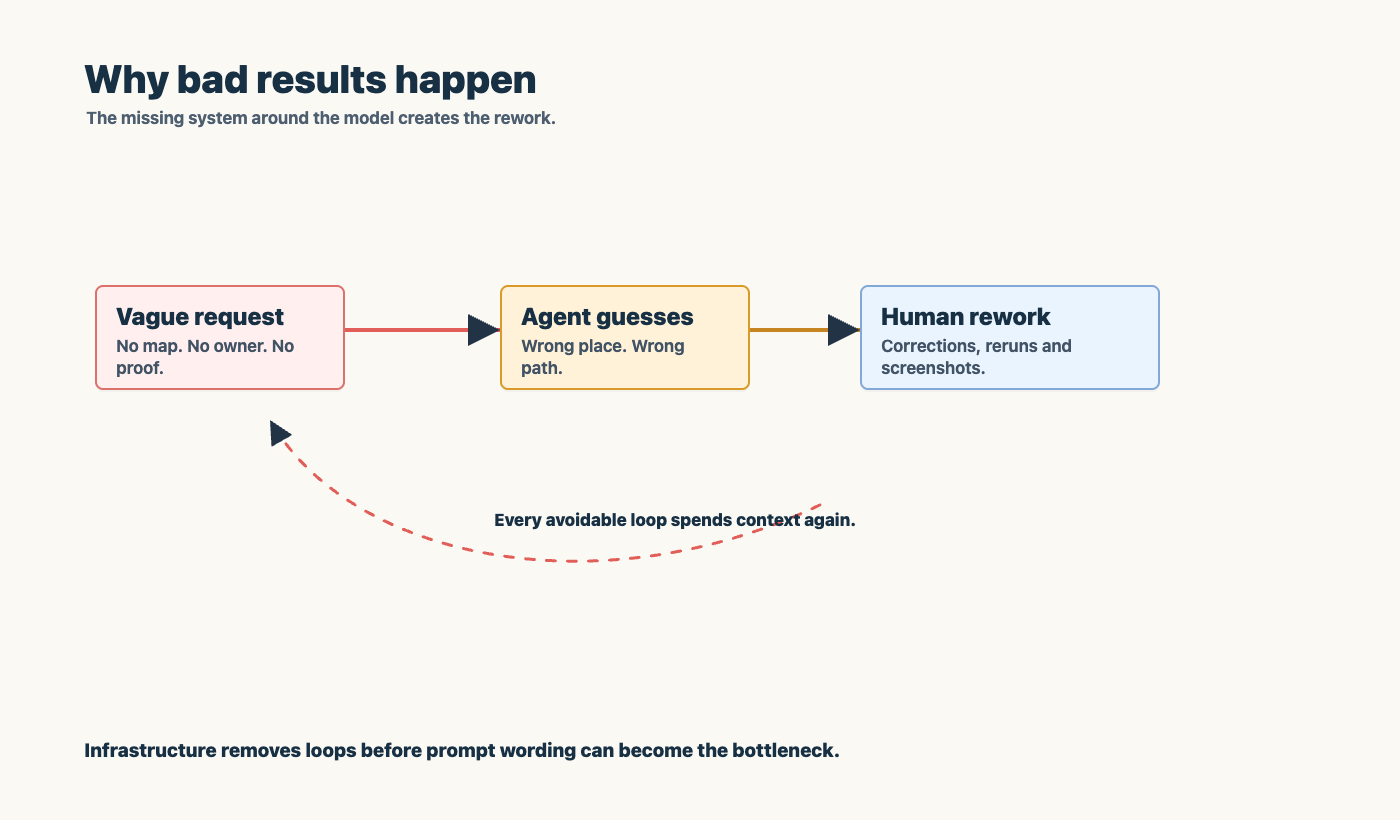
Most bad agentic results are not mysterious. They happen when someone asks an agent to behave like a professional team, but gives it none of the machinery a professional team depends on.
The task exists only in chat. There is no owner, status, history, acceptance criteria, or audit trail.
The source of truth is unclear. The agent sees a live host, a local checkout, a branch, a stale note, and a few half-remembered commands, then has to guess which one matters.
The context is too broad or too vague. More text is added, but the system still does not know which runbook applies.
The proof step is optional. The agent produces plausible code or prose, but nobody has forced it to run the relevant tests, open the browser, inspect logs, or verify the deploy.
This is not a model intelligence problem first. It is an operating model problem.
The useful question is not “how do I prompt the agent better”. The useful question is “what infrastructure routes a work request into the right evidence path”.
What the contract must decide
An agent.md worth caring about answers boring questions very explicitly.
- Where am I working?
- Which repository is the deployable source of truth?
- Which host is development, which host is production, and which host is only a runner?
- Which tools are legitimate for this task?
- Which files are operating rules and which files are implementation details?
- What must be documented when a lesson is learned?
- What proof is required before the work can be called done?
- What is never acceptable, even if it would make the current task look finished?
That last question is where quality starts.
In my own setup, agent.md says that origin/main is the deployable truth, web changes require browser evidence, host-to-host copying is not a normal deploy path, fallback-by-default is not a production architecture, and certain kinds of work have dedicated runbooks. It also points the agent to the backlog, pipeline tools, DNS tooling, backup scripts, browser-capture flow, and domain-specific docs.
The point is not to make a long instruction file for its own sake. The point is to make the path of work obvious enough that the agent does not invent a new process every time.
Access is not magic
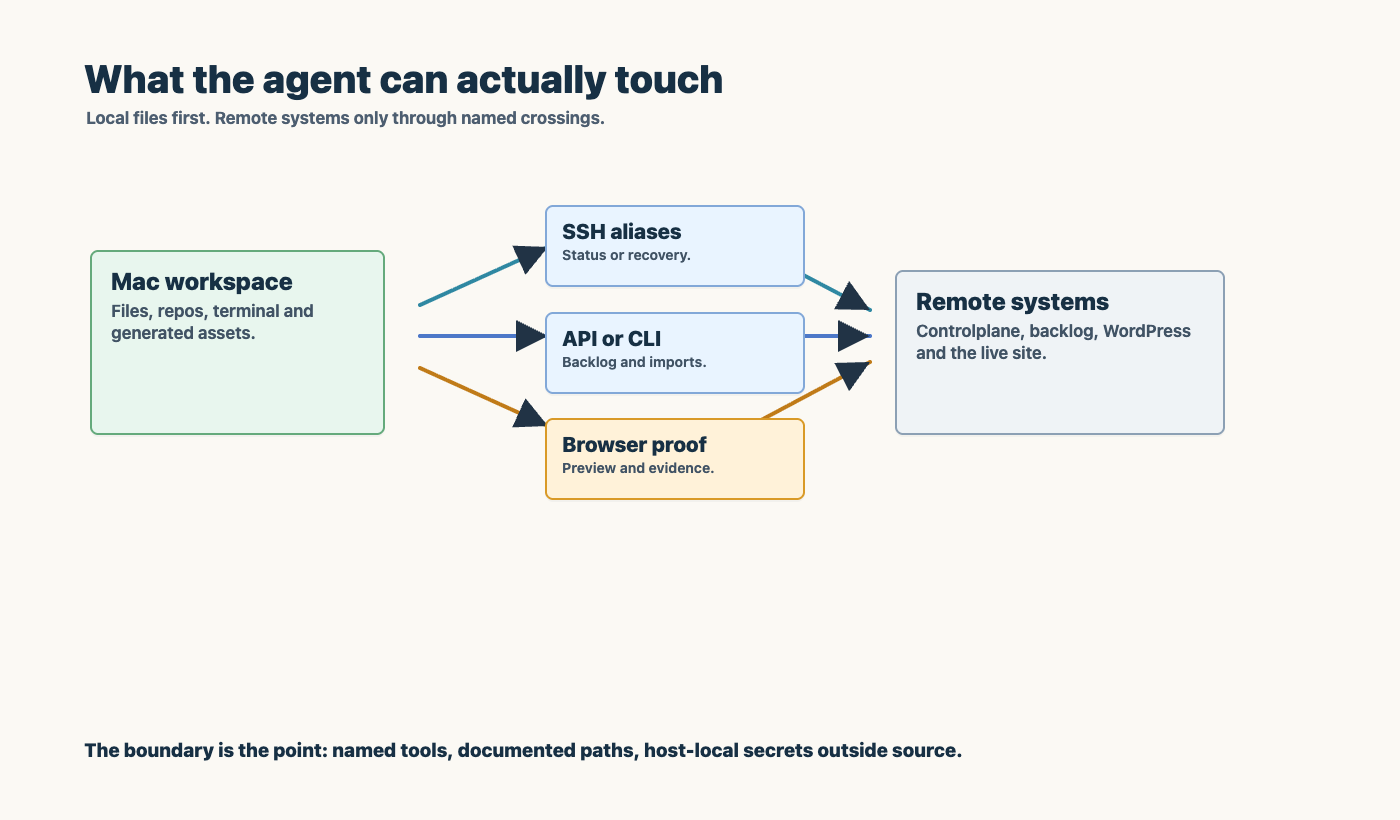
People often imagine two extremes: either the agent is only a chatbot that suggests commands, or it is an all-seeing thing with unlimited access.
The useful middle is more concrete.
The agent works in a workspace. It can inspect a managing Git repository with rules, runbooks, scripts, desired-state files, and lesson documents. It may run commands on the local machine. Sometimes it may connect to another system over SSH. More often, it interacts through a pipeline, an API, or a browser validation script.
That means the important design question is boundary design.
An agent does not need every credential. It needs the right role for the task. If it can deploy through a pipeline, the pipeline should carry the production access. If it can inspect browser state through a capture script, it does not need to improvise a manual test flow. If it can update DNS desired state through a repo tool, it should not log into a provider console as a human.
Good agentic work feels powerful because it is bounded, not because it is unlimited.
Security is role design
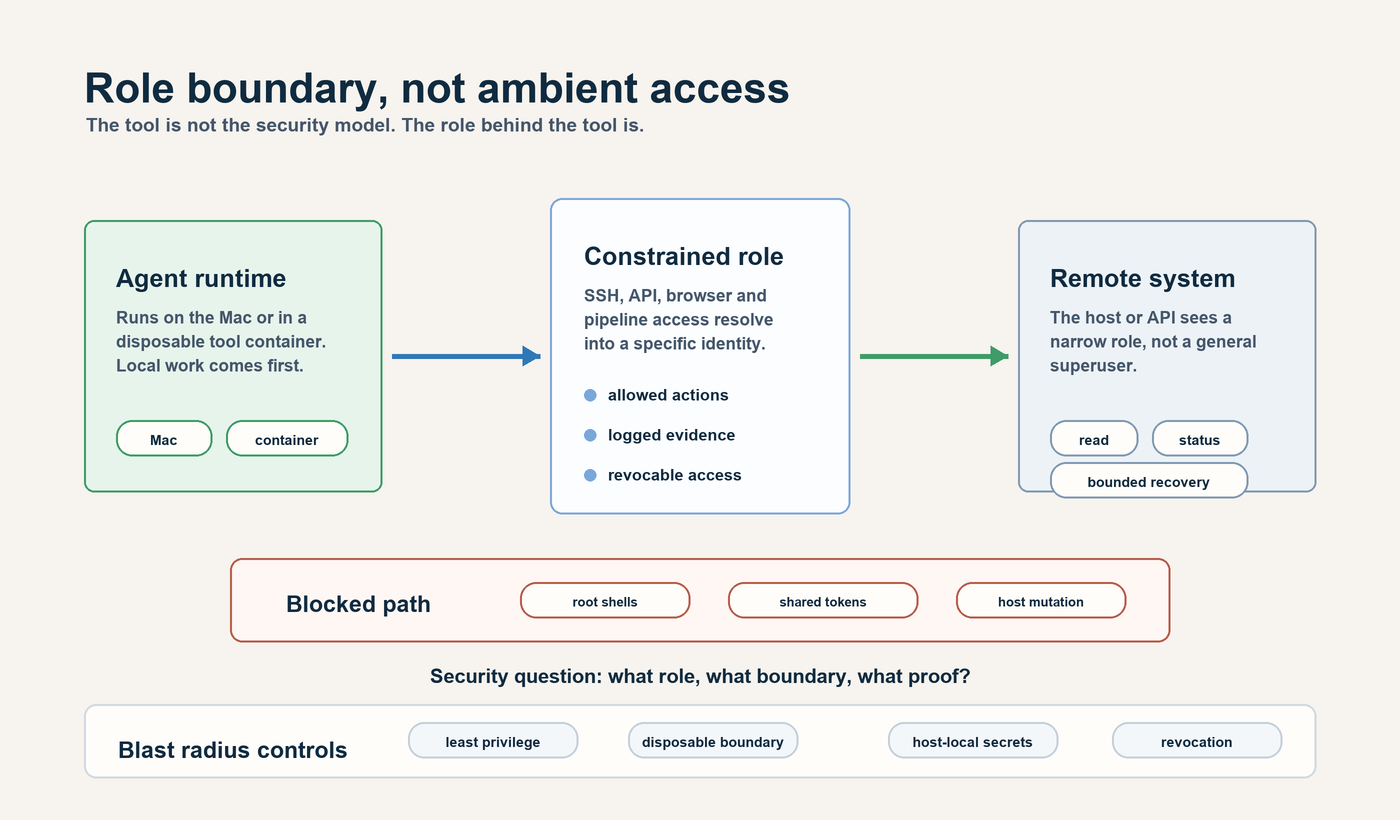
Agentic work does not create a new physics of security risk. A shell is still a shell. An SSH key is still an SSH key. An API token is still an API token.
What changes is frequency and speed.
More work is attempted. More paths are explored. More commands are run. An agent is also good at finding a route when the first route fails. That is useful in engineering and dangerous in weakly governed systems.
So the question is not “does the agent have SSH”. The question is what role that SSH identity has.
An SSH key into a restricted user inside a disposable container is very different from a key into a privileged long-lived host. A token that can open a pull request is different from a token that can mutate production state. A browser testing account is different from a tenant admin account.
The same role discipline we already know from infrastructure applies here:
- least privilege
- short-lived credentials
- scoped service accounts
- disposable execution contexts
- audited command paths
- separation between development, deployment, and production control
- no hidden fallback path that bypasses the real release process
This is why agent.md should say what kind of access is legitimate, not only what command to run.
The real token eater is iteration
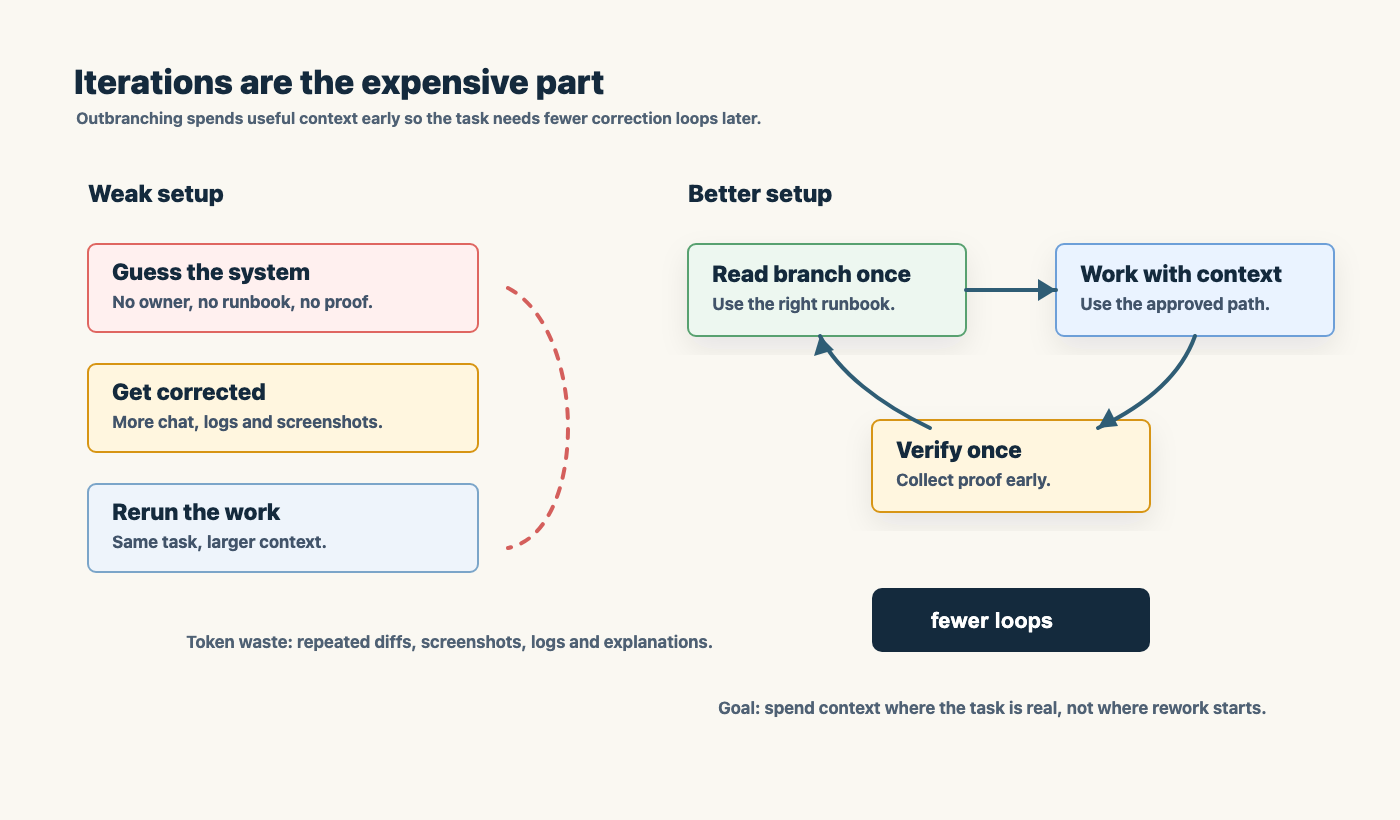
People worry that a serious agentic workflow must use too many tokens because it reads runbooks, checks files, opens browsers, captures screenshots, and writes evidence.
That is the wrong comparison.
The expensive path is not “the agent read the right context”. The expensive path is “the agent guessed, did the wrong thing, got corrected, guessed again, broke layout, got corrected again, then finally discovered the rule it should have read first”.
Iteration is the real token eater.
Visual verification is expensive, especially screenshots. But it is also where many frontend lies die. A page can have green tests and still have overlapping text. A code block can exist and still be unreadable on mobile. A browser preview can reveal broken images that a Markdown check will never see.
The job is not to minimize every single token. The job is to reduce wasteful correction loops.
Outbranching from agent.md helps. The root file should not contain every command in the universe. It should route the agent to the specific runbook for the task: browser testing, pipeline release, DNS work, PCB design, Broadcom documentation, backup flow, or whatever domain is actually relevant.
Good context is cheaper than repeated confusion.
How work should flow
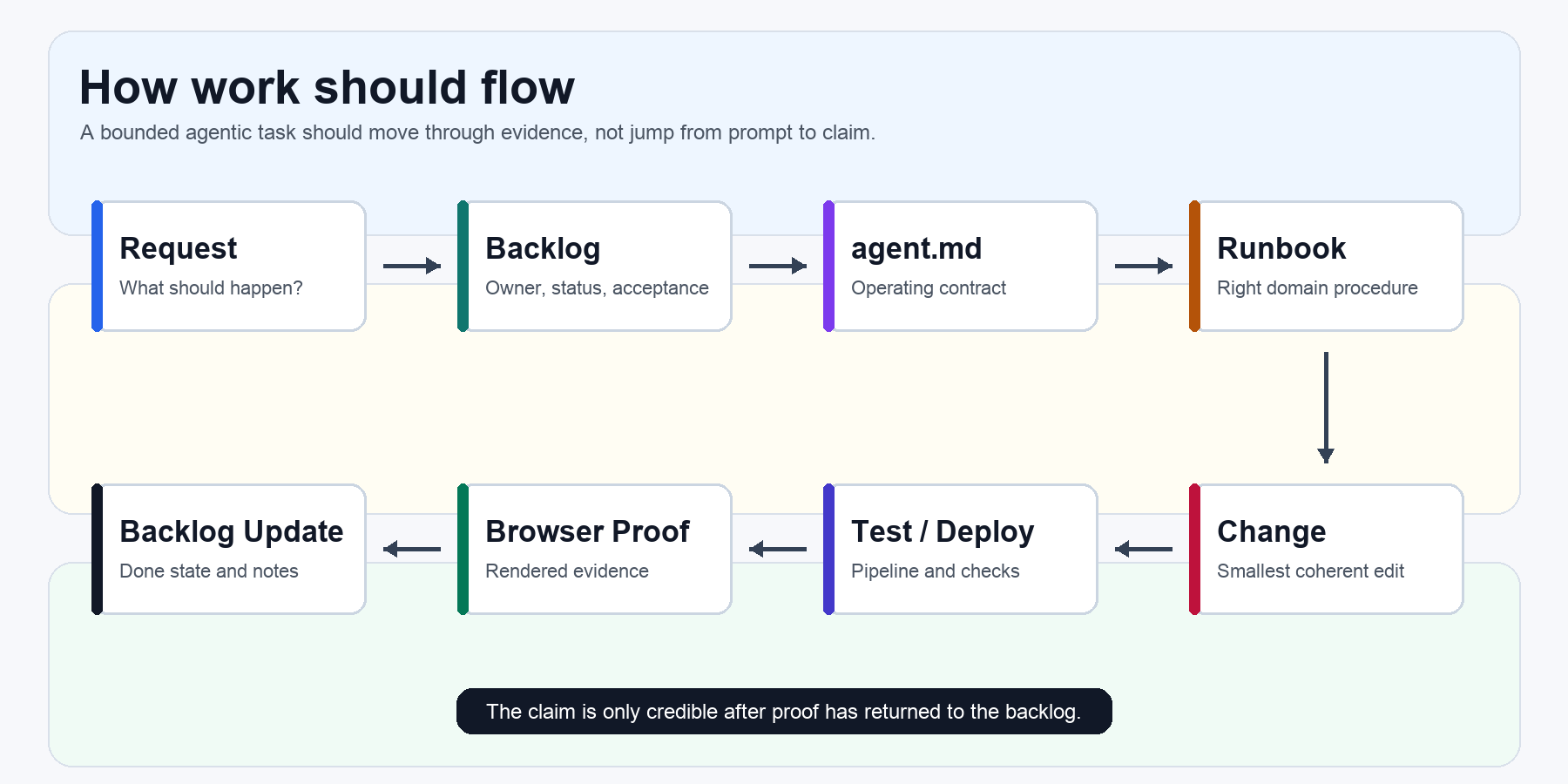
When I ask for work, I do not want the agent to jump straight from request to finished claim.
I want a path:
- the task goes into the backlog, so it has an owner, status, priority, and a place to store progress
- the agent orients itself by reading the root operating contract, checking the repo state, and finding the relevant runbook
- the change stays as small as reasonably possible and follows the existing codebase
- verification produces evidence: screenshots, DOM output, console logs, page errors, failed requests, API responses, targeted tests, deploy status, or rendered-page review
- the backlog gets updated and the repo is left clean
That may sound formal, but it is less work than recovering from invisible drift.
One deployable truth
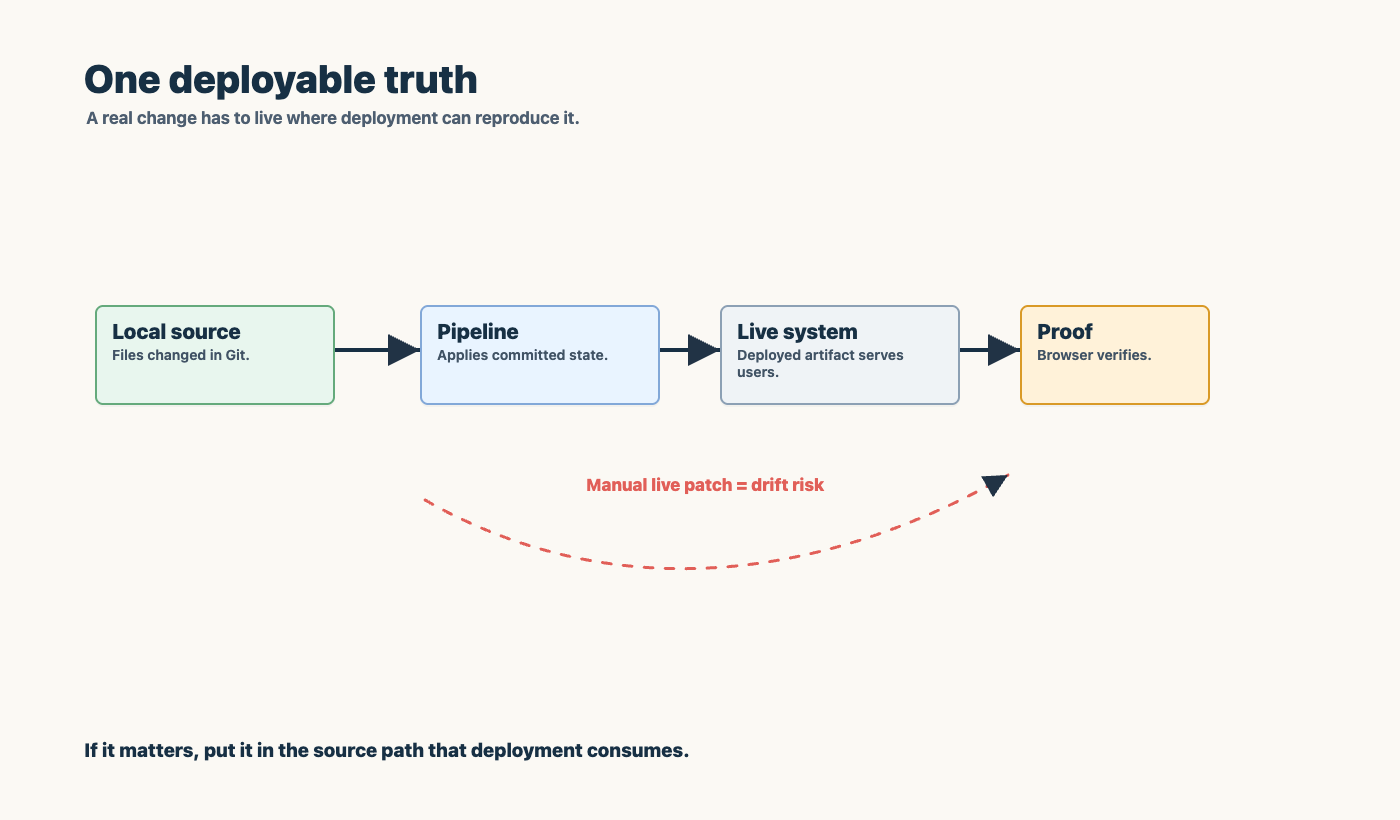
Agentic work gets messy fast when there are multiple truths.
There is the local file. The branch. The deployed host. The admin panel. The pipeline artifact. The browser preview. The note in chat.
If those drift apart, the agent becomes a high-speed confusion amplifier.
That is why I care so much about one deployable truth. The normal path should be:
- change source
- commit intentionally
- push
- let the pipeline deploy
- verify the deployed artifact
- record the proof
Host-local fixes are sometimes necessary in emergencies, but they should not become the operating model. If a fix matters, it goes back to source. If a lesson matters, it becomes a test, a runbook, or an operating rule.
Chat is a terrible system of record. Git, backlog, tests, and runbooks are better.
The backlog is machinery
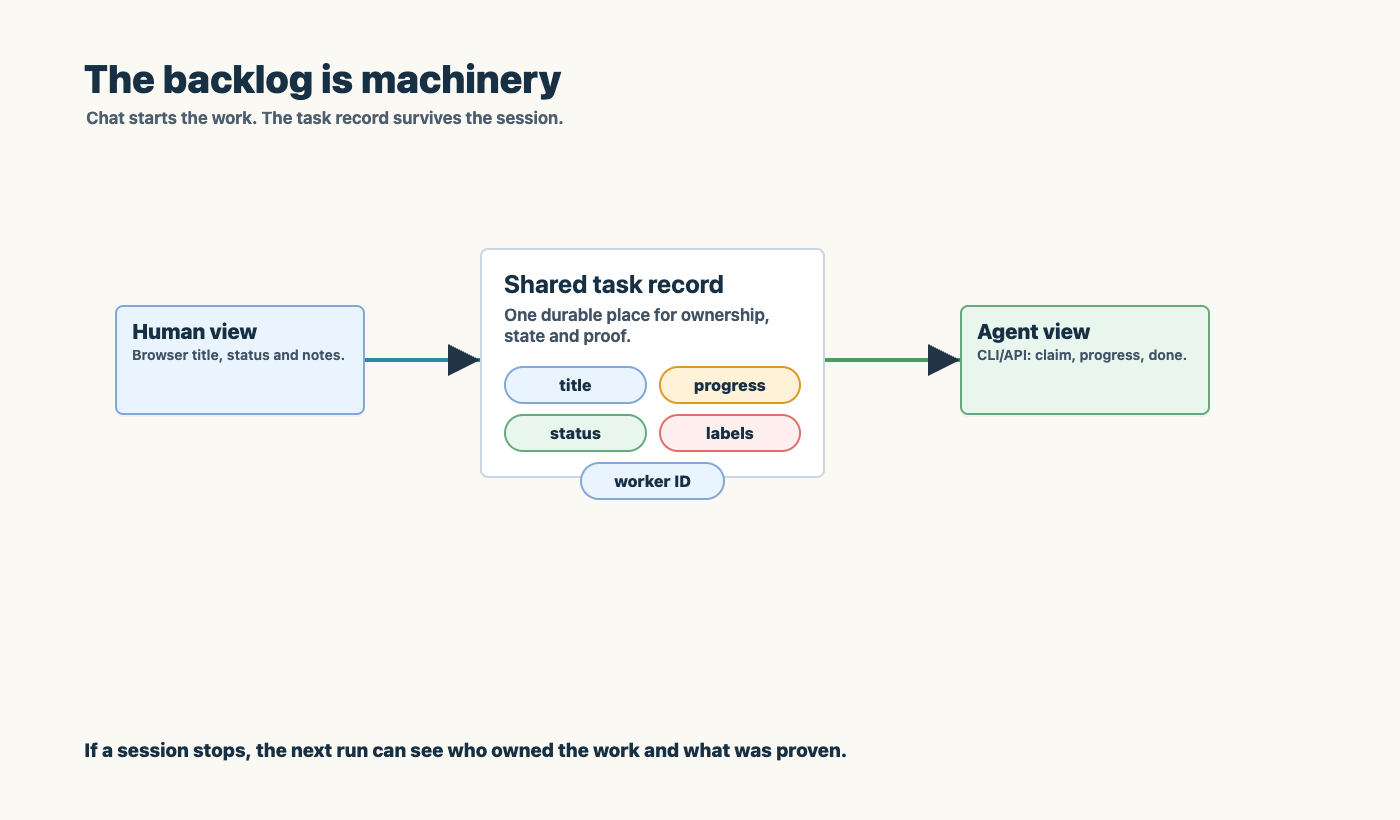
The backlog is not administrative decoration. It is part of the machine.
For a human, the backlog is a browser view. I can read tasks, review priority, and decide what matters next.
For the agent, the backlog is also an API or CLI. It can claim work, update progress, release a lock, or mark a task done.
That shared interface solves a practical problem: the work no longer lives only in a conversation. If a run stops halfway through, the next run can see the task, status, worker, and progress note. If I ask for a release, there is a record that the release happened. If the agent is blocked, it can say where and why.
That sounds mundane until you run more than one agentic task in a day. Then it becomes the difference between a system and a mess.
Agent Drift
There is a second kind of drift that deserves its own name: Agent Drift.
Configuration drift happens when systems slowly disagree with the desired state. Agent Drift happens when different agent runs learn different lessons and write them into different places.
One run discovers that browser validation needs a special login path. Another run discovers that DNS changes must go through a desired-state file. A third run learns that a host-local workaround is dangerous. If those lessons remain in chat, or get written into random notes, the next agent may not inherit them.
Now the agents are not only changing code. They are changing the operating model in contradictory ways.
The fix is boring and important:
- durable lessons go into the right runbook
- recurring bugs become tests
- new access paths are documented where future work will look
- old guidance is superseded, not silently deleted
- root rules route to deeper docs instead of duplicating everything
An agentic engineering environment should learn, but it should learn through controlled memory. Otherwise you do not get organizational learning. You get sediment.
AAA is a design constraint
One of my strongest rules is that the agent should take the AAA path: secure, scalable, enterprise-class architecture with no shortcuts.
That does not mean every lab has to be production. It means the architecture should not become worse just because the agent wants the task to look done.
The agent should not normalize insecure transport. It should not add certificate bypasses as a steady state. It should not invent fallback logic that hides broken infrastructure. It should not patch a live host and leave source behind.
This is a style of programming as much as a security rule.
It pushes the agent toward explicit contracts, environment-based configuration, stateless processes where possible, real backing services, reproducible startup, and tests that capture the bug that was fixed.
The current task is never the whole system. The agent has to leave the system more coherent than it found it.
Learning without mythology
When people say “the agent should learn”, they often mean something vague. I want something more operational.
A system learns when the next run has better structure than the previous run.
That can happen through:
- a new regression test
- a clearer runbook step
- a stricter validation script
- a documented access path
- a backlog note that preserves handoff state
- a rule that prevents a repeated failure mode
The learning should live where the next agent will actually read it. A PCB lesson belongs in a PCB manifest. A browser testing lesson belongs in the browser testing runbook. A pipeline lesson belongs in the release workflow. A security access lesson belongs in the tooling and access journal.
This is how agentic quality compounds. Not through vibes. Through memory attached to the system.
Browser proof is proof work
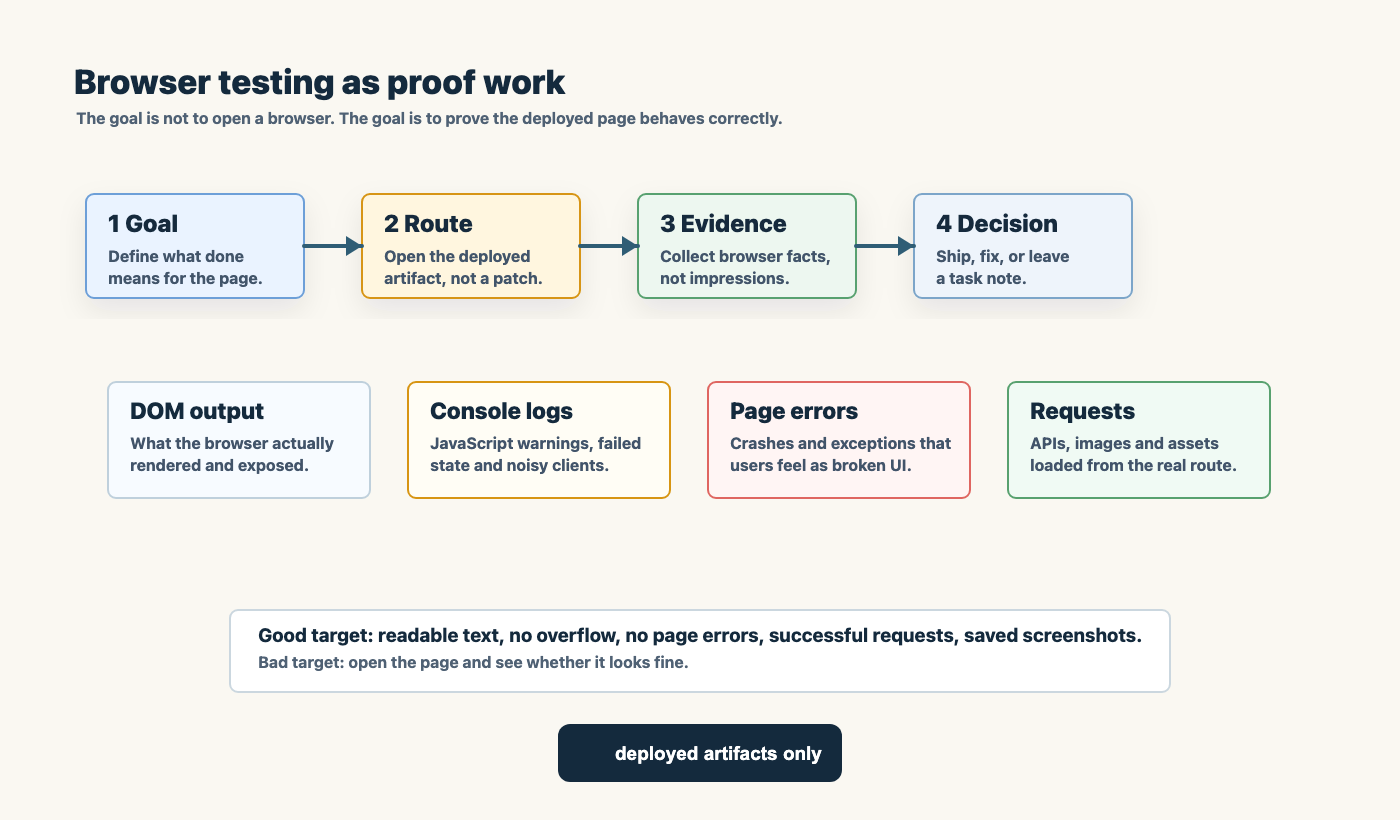
For web work, I do not trust a final answer that says “it should look right”.
The browser has to be part of the proof.
That means inspecting the rendered page, not only the source. It means checking screenshots, DOM output, console logs, page errors, failed requests, API responses, and performance data. It means mobile as well as desktop when layout is involved.
This matters because frontend bugs are often visual and contextual. Text can overlap only at one width. A copy button can float in the wrong place only while scrolling. An image can be present in Markdown but broken in WordPress. A code block can be syntactically correct and still unusable on a phone.
Agents are very good at producing plausible claims. Browser proof turns plausibility into evidence.
A short hardware example
PCB development is useful as a small example because it shows that this is not only a software pattern.
If an agent works on a board, it should not just open KiCad and start moving traces. It needs the board manifest, design rules, cost constraints, lessons from prior revisions, fabrication assumptions, and verification expectations. If it discovers a routing pattern that prevents a repeated failure, that lesson should go into the durable PCB manifest.
That is the same pattern again.
The operating contract routes the work into the right domain memory. The result is not only one better board. It is a better next run.
What others can copy
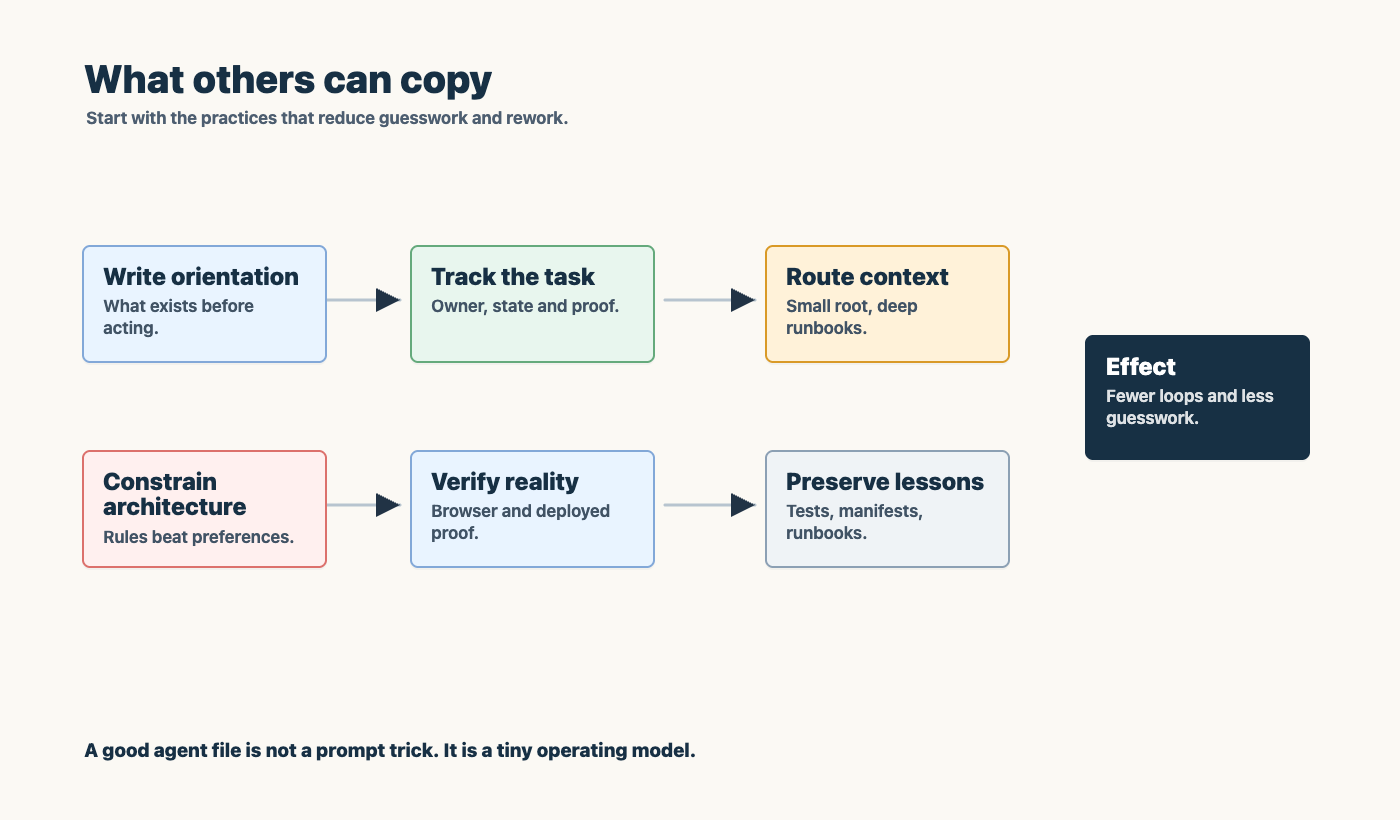
The exact files in my setup are personal. The pattern is portable.
If you want better agentic work, start with a small operating contract:
- name the source of truth
- define the normal deploy path
- make task tracking mandatory
- document which tools are legitimate
- separate local work, runners, and production systems
- require proof for browser-visible changes
- put domain lessons where future runs will find them
- mark lab shortcuts as lab shortcuts
- forbid shortcuts that make production architecture worse
Then branch out from the root file. Do not make one giant instruction document. Use it as a router.
The thesis is simple: agentic engineering is infrastructure, operations, and knowledge management before it is prompting.
Durable systems beat chat memory.