Partially AI-modified / AI transparency: This publication is AI-assisted and human-reviewed. Constantin Korte assumes editorial responsibility. See AI Transparency.
TL;DR
VCF 9 matters because Namespaces, VM Operator, VPCs, fleet operations, and multi-AZ designs make the platform easier to govern and consume.
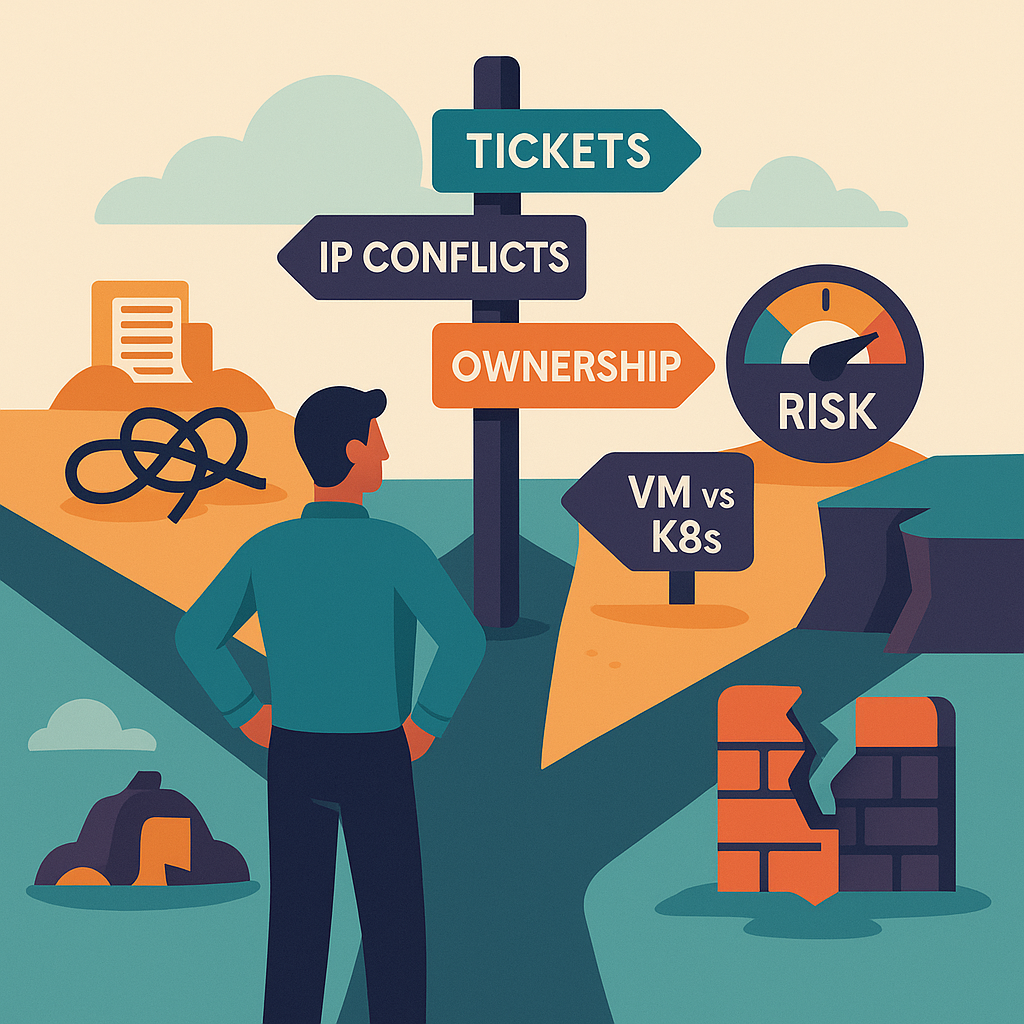
Hugo stands in for many of our customers: he’s responsible for a platform that must be secure, compliant, and agile all at once.
But his everyday reality is full of real obstacles. Four typical examples:
1. The Ticket Desert
A developer needs a new subnet. The request passes through three departments, each reviewing, approving, and forwarding it.
By the time the VLAN is ready, the sprint is already over – and the planned feature is scrapped.
The result: shadow IT and growing frustration in the team.
2. Shared Network, Shared Pain
All teams share a single IP range.
One duplicate hostname is enough, and monitoring collapses for everyone.
Suddenly developers, NetOps, and admins are firefighting together – and tripping over each other in the process.
3. Roles Without Boundaries
NetOps, vSphere admins, and developers all run their own scripts.
But no one has the full picture. A firewall port stays open – unnoticed until compliance shows up at audit time.
The risk is always present.
4. No Guardrails, Full Risk
“Just a bit more CPU” – and suddenly a cluster consumes everything it can get.
The finance department’s database suffers, the ESXi farm runs at the limit, alarms are firing.
Without clear guardrails, the platform loses its stability.
What VCF 9 Really Changes
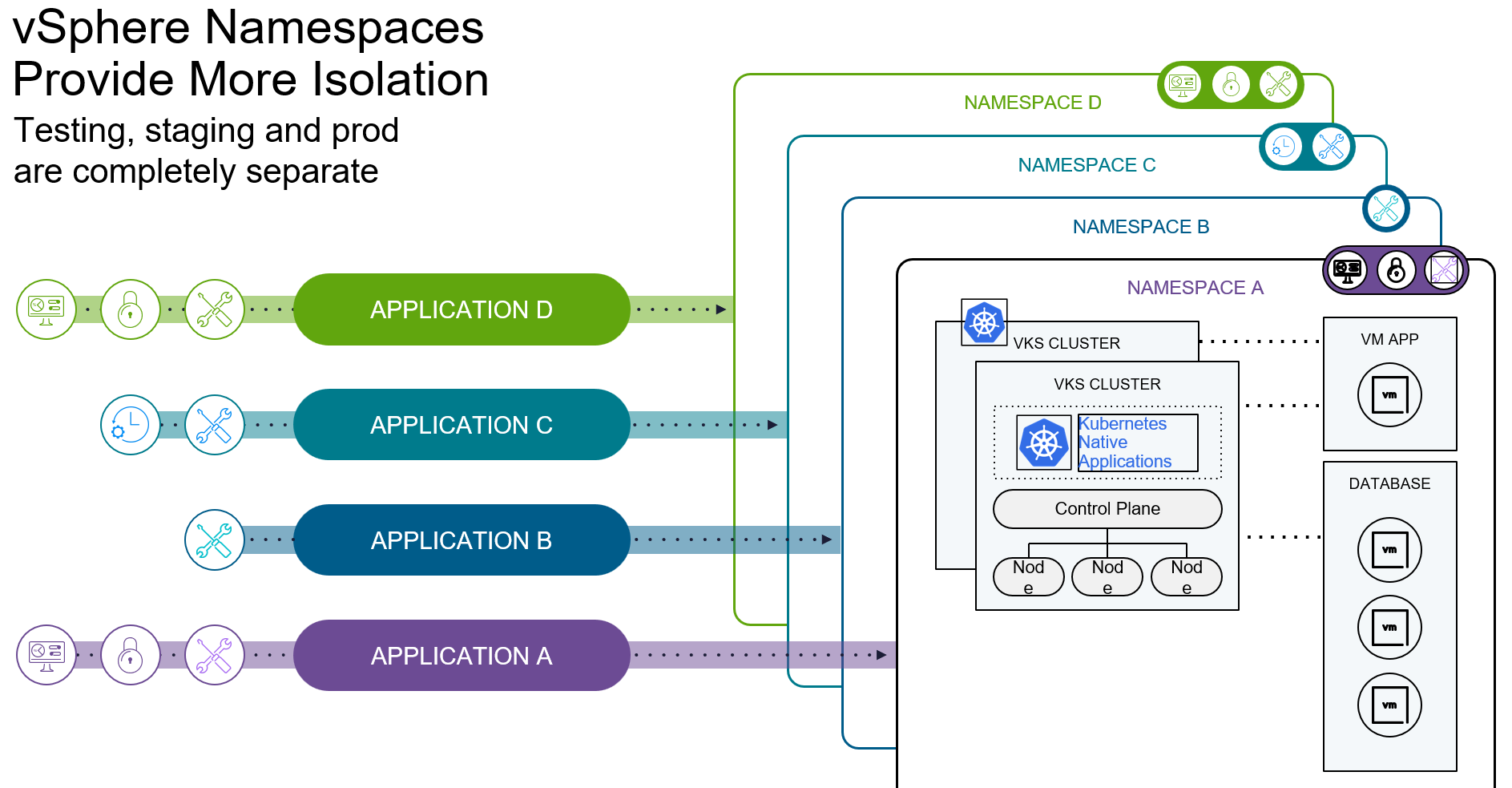
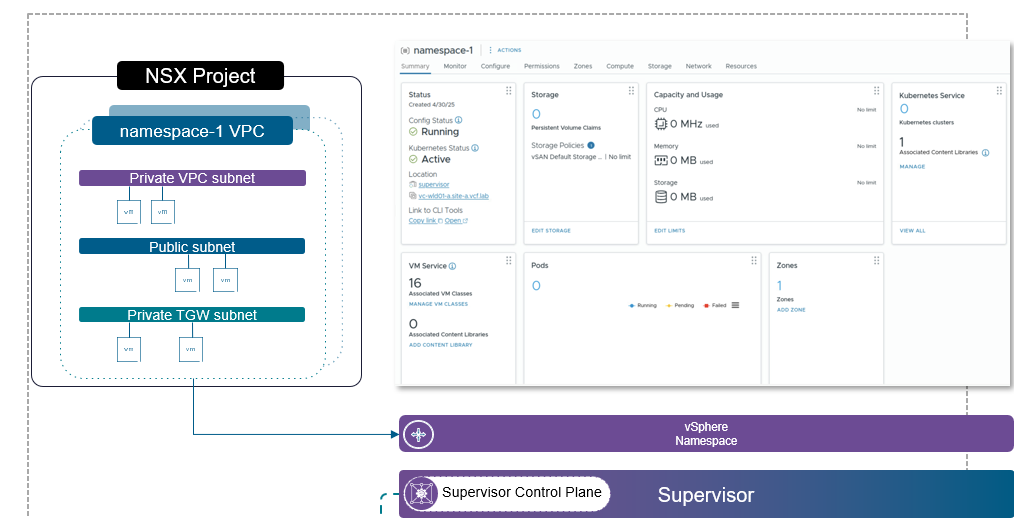
vSphere Namespaces
Namespaces are more than mere technical isolation – they give customers something like a mini data centre.
A project team gets its own resources, shielded from the rest of the infrastructure, with quotas and policies that cannot be exceeded.
That ensures no one can monopolise the platform – while the VI admin still retains full control.
VM Operator
The VM Operator makes VMs declarative.
A developer writes in YAML what sort of VM they need – and it spins up in seconds.
That means VMs can also be used like containers for short-lived, one-off tasks, instead of going through the full, imperative lifecycle of a traditional VM.
It changes how we think about VMs: they are no longer just “pets” but can be used as dynamically as Kubernetes workloads.
Virtual Private Clouds (VPCs)
With VPCs, VCF 9 allows customers to act as service providers themselves.
Teams can build complex network architectures in self-service – isolated, secure, and scalable.
This solves two classic problems of private clouds: the lack of multi-tenancy and the difficulty of network integration.
For organisations delivering multi-tenant services to internal or external customers, it’s a real breakthrough.
Fleet Management with VCF Automation
With VCF Automation (vRA), clarity returns: clusters can be run at scale and consistently.
Business logic is built directly into platform operations – whether for updates, rollouts, or compliance checks.
That reduces manual effort and lets customers manage their fleets in the same way as modern public cloud platforms.
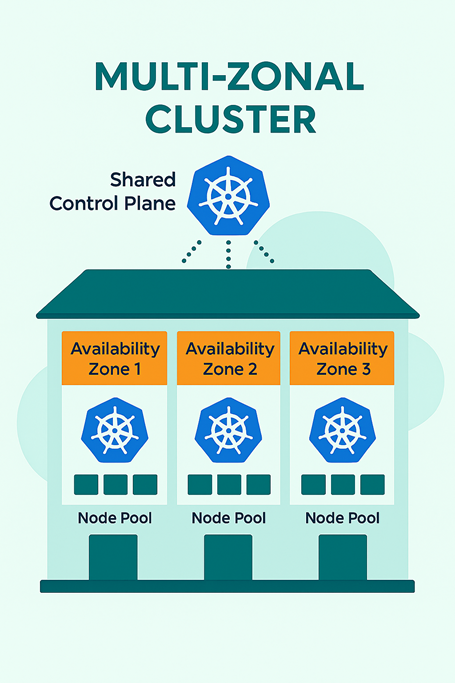
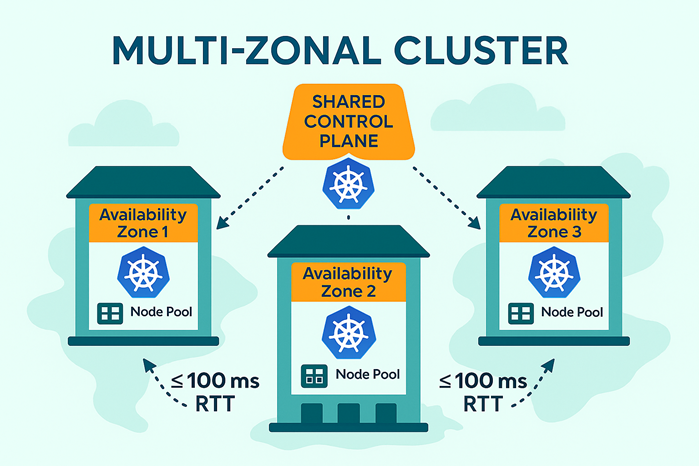
Multi-AZ Topologies
Multi-AZ is not just an architectural feature – it changes the developer’s perspective.
For the first time, they see the actual topology of the infrastructure and can design their applications to be topology-aware.
That makes the platform more cloud-native, letting developers create availability models similar to those used in hyperscaler regions.
For us, Multi-AZ topologies are the step that brings VMware closest to the region models of major providers – and there’s more to come.
Upstream Alignment
One of the key strengths of VKS: it stays very close to upstream Kubernetes.
A Venn diagram explains it well:
In real multi-cloud environments, the lowest common denominator of features often dictates what’s possible.
Many abstraction layers set that bar so low that valuable platform features are lost.
With VKS, it’s different:
Customers can use the full native features of vSphere and NSX whenever they need them.
At the same time, they can always fall back to the unified subset of Kubernetes when portability across platforms takes priority.
Unlike distribution-based approaches that over-abstract, here the choice remains with the customer.
That makes VKS a Kubernetes service that fits into VMware inventory, policy, and operations – while remaining open and CNCF-compliant.
My Talk
I recently gave a talk on exactly these themes: how VCF 9 and VKS work together to make complex realities simpler and safer.
Partially AI-modified / AI transparency: This publication is AI-assisted and human-reviewed. Constantin Korte assumes editorial responsibility. See AI Transparency.
TL;DR
One DevEnv YAML can describe a full VCF lab handoff: tools VM, database VM, VKS cluster, packages, DNS, certificates, ingress, and app deployment.
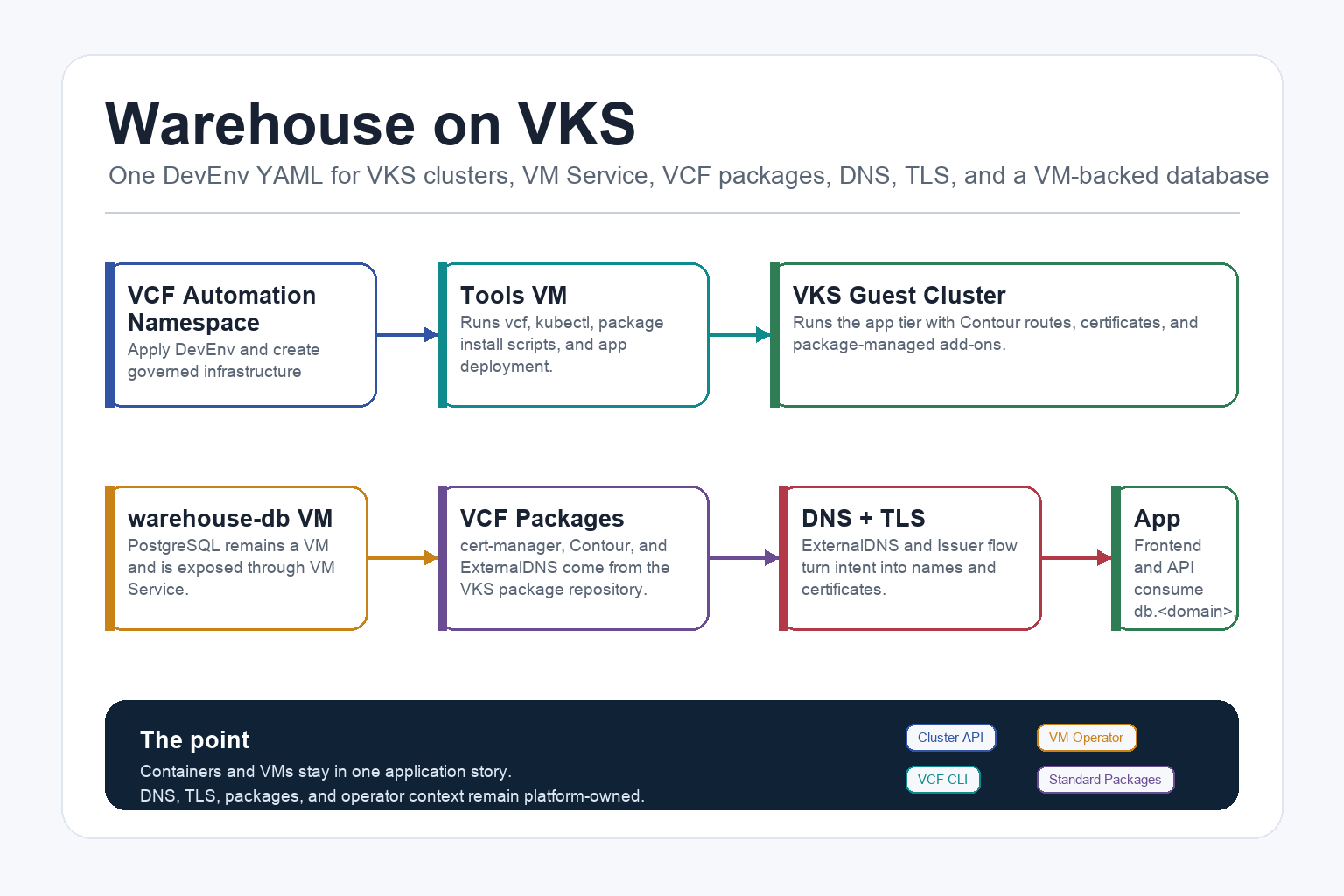
This is a practical Warehouse lab on VMware Cloud Foundation. The point is not to show a pretty Kubernetes demo. The point is to show what a real platform handoff can look like when VKS, VM Service, VCF CLI, DNS, certificates, package installation, and VM-backed services are treated as one operating model.
The happy path is deliberately simple: apply one DevEnv YAML into a VCF Automation namespace. That single YAML creates the tools/code VM, the database VM, the VKS cluster request, the package-installation scripts, the app manifests, the DNS and certificate intent, and the service exposure. If the platform infrastructure is already ready, this feels close to “run the YAML, go to the tools VM, run the operator steps, and the lab comes up.”
This article assumes VCF itself is already deployed and usable. In practical terms, that means VCF Automation, a Supervisor/VKS path, a project or namespace for the lab, package access, DNS, registry access, and certificate material are available or can be prepared. If VCF is not set up yet, start with the Broadcom VCF deployment path first, then come back here once the platform can accept DevEnv objects in a governed namespace.
Most of the generated files are not things you manually paste one by one. The operating systems execute the automatic bootstrap scripts during VM startup. The manual part is intentionally small: connect to the tools VM or its browser code surface, then run the three operator scripts that create the cluster, install platform packages, and deploy the application. Those three steps could also be moved into auto-start later, but keeping them explicit in this article gives clean checkpoints for learning and debugging.
The best experience comes after the prep work has been done once. ExternalDNS can update the zone, cert-manager has issuer material, the registry and package repository are reachable, and the VCF token/context path is known. From that point onward, the YAML becomes the handoff artifact you can repeatedly apply in a lab without re-learning the whole platform every time.
The reader I have in mind has maybe written a little Python and has heard words like API, token, kubeconfig, DNS, and VM. You do not need to be a VCF specialist to follow the article. I will keep the contexts explicit, because most failed first attempts are not caused by one bad command. They are caused by running the right command from the wrong place.
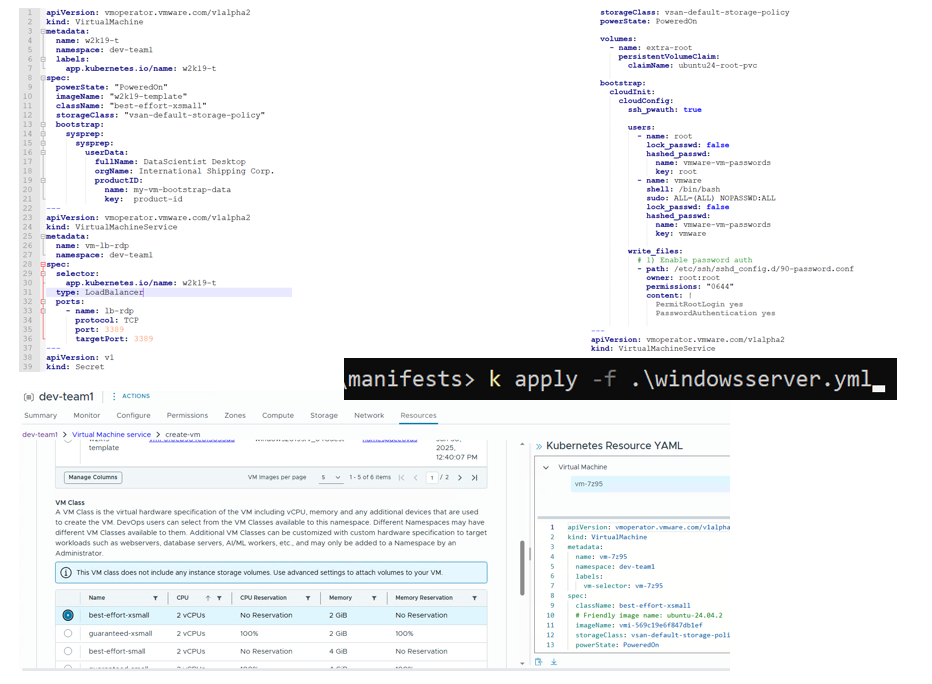
The DevEnv file is the handoff artifact. You apply one YAML into the VCF Automation namespace, and cloud-init turns that into the operator scripts and manifests on the VMs.
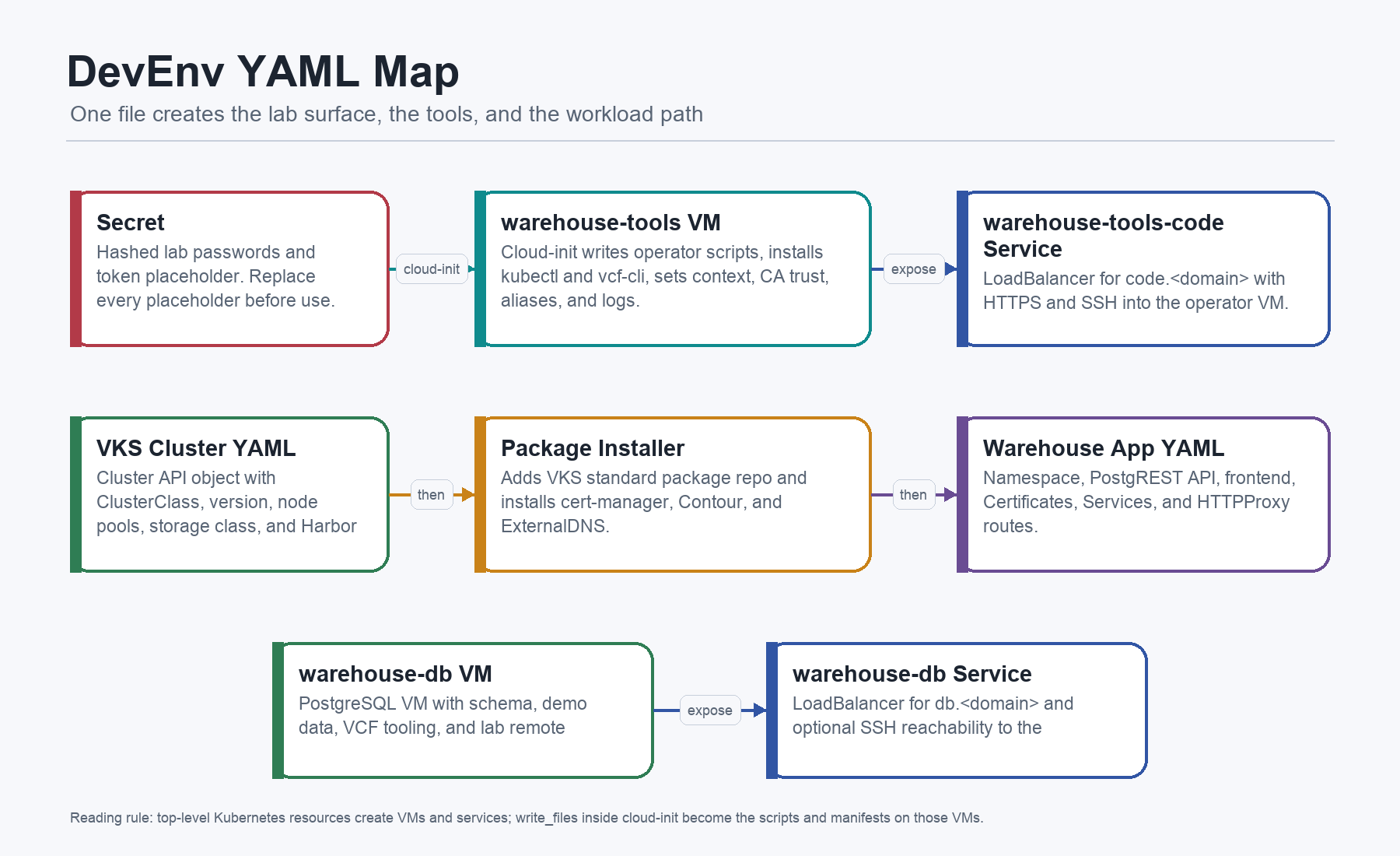
At the top level, the current devenv.example.yaml creates five Kubernetes resources:
Secret ubuntu-jumpserver-bootstrap-secret: lab password hashes for the VM users.
VirtualMachine warehouse-tools: operator VM with kubectl, vcf-cli, CA trust, context setup, package scripts, app manifests, and optional code-server assets.
VirtualMachineService warehouse-tools-code: LoadBalancer for code.<app-domain> exposing HTTPS and SSH to the tools VM.
VirtualMachine warehouse-db: PostgreSQL VM with schema, demo data, VCF tooling, and lab remote access.
VirtualMachineService warehouse-db: LoadBalancer for db.<app-domain> exposing PostgreSQL and optional SSH to the DB VM.
Inside the two VirtualMachine objects, cloud-init writes the actual working files. That is the important detail. Paths like /home/vmware/20-install-platform-packages.sh are not files you need to fetch from a second repo. They are created by the DevEnv itself.
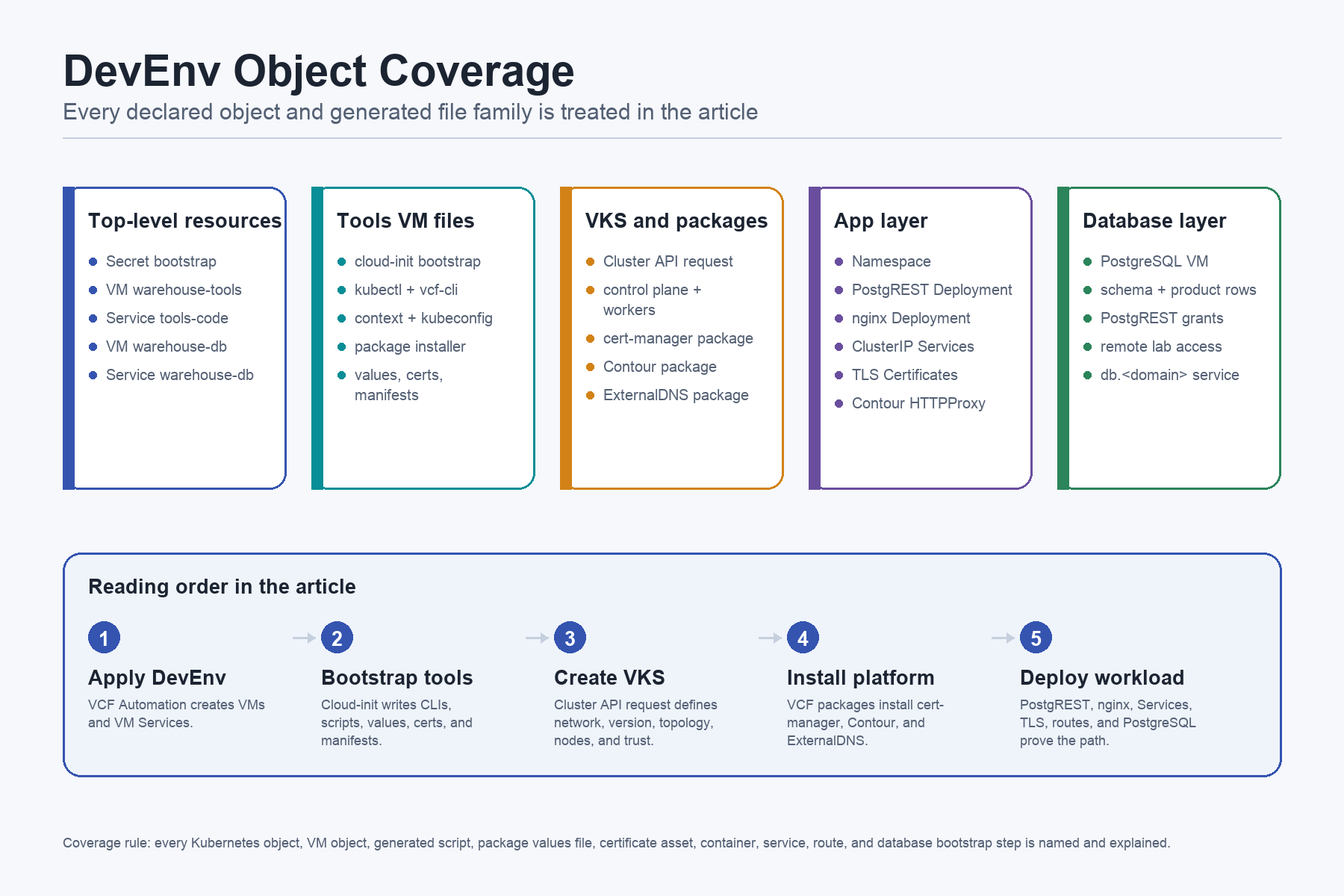
The Complete Object Inventory
This is the review checklist for the file. If something is declared in the YAML, it should either be part of this inventory or be an implementation detail of one of these rows.
The top-level objects are the VCF Automation contract. They create the lab surfaces:
VirtualMachineService warehouse-db: LoadBalancer and DNS bridge for PostgreSQL and optional SSH.
The tools VM writes the platform bundle. These are not decorative files. They are the runnable operator model:
/etc/ssh/sshd_config.d/90-password.conf: makes the lab VM reachable with the declared lab account model.
/etc/vcf-api-token: local token placeholder used by the VCF context scripts.
/etc/profile.d/10-xdg.sh: keeps CLI config, cache, and state paths predictable.
/etc/profile.d/20-kubectl-alias.sh and /etc/bash.bashrc.d/20-kubectl-alias.sh: add kubectl completion and the k alias in login and interactive shells.
/usr/local/share/ca-certificates/example-root.crt, /usr/local/share/ca-certificates/vcf-auto-ca.crt, and /usr/local/share/ca-certificates/ops-fleet-ca.crt: put platform and lab trust roots into the OS trust store before CLI calls.
/etc/profile.d/30-vcfa-token.sh and /etc/bash.bashrc.d/30-vcfa-token.sh: export token variables expected by VCF and kubectl auth flows.
/home/vmware/bootstrap.sh: runs every automatic bootstrap script in order and writes logs.
/opt/bootstrap.auto.d/00-tools-setup.sh: installs base packages, kubectl, vcf-cli, completion, CA trust, and the base VCF context.
/home/vmware/10-create-cluster.sh: applies the VKS Cluster, waits for readiness, registers the JWT authenticator, and retrieves kubeconfig.
/home/vmware/20-install-platform-packages.sh: adds the package repo and installs cert-manager, Contour, and ExternalDNS.
/home/vmware/40-deploy-app.sh: applies the app manifest, waits for Certificates, waits for Deployments, and prints HTTPProxy status.
/opt/warehouse-platform/extdns.values.yaml: ExternalDNS RFC2136 values for service, ingress, and Contour HTTPProxy sources.
/opt/warehouse-platform/contour-data.values.yml: Contour and Envoy values, including Envoy as a LoadBalancer Deployment.
/opt/warehouse-platform/k8s/secret-supervisor-subca.yaml: cert-manager TLS Secret for the SubCA.
/opt/warehouse-platform/k8s/clusterissuer-supervisor-subca.yaml and /opt/warehouse-platform/k8s/cluster-issuer-supervisor-subca.yaml: primary and compatibility filenames for the same ClusterIssuer.
/opt/warehouse-platform/certs/k8s-subca-fullchain.pem and /opt/warehouse-platform/certs/k8s-subca.key: optional raw PEM path when creating the SubCA Secret from files.
/opt/warehouse-platform/k8s/code-cert.yaml: optional Certificate for code.<app-domain>.
/opt/warehouse-platform/scripts/install-coder.sh: optional code-server installer and systemd unit.
/opt/warehouse-platform/k8s/cluster-warehouse.yaml: VKS Cluster API request.
The DB VM has its own smaller bootstrap inventory:
/etc/ssh/sshd_config.d/90-password.conf, /etc/vcf-api-token, alias files, CA files, and token-export files: same lab reachability, trust, and VCF CLI usability pattern as the tools VM.
/home/vmware/bootstrap.sh: runs automatic DB bootstrap scripts and writes logs.
/opt/bootstrap.auto.d/00-vcf-bootstrap.sh: installs vcf-cli, kubectl, optional helpers, and the VCF context on the DB VM.
/opt/bootstrap.auto.d/10-db-setup.sh: installs PostgreSQL, creates the acme role, database, table, rows, and grants.
/opt/bootstrap.auto.d/15-db-remote-access.sh: opens PostgreSQL for lab remote access through scram-sha-256.
The embedded manifests are the objects the later sections explain in detail:
cluster-warehouse.yaml: Cluster warehouse with network, topology, version, trust, control plane, and worker pool.
warehouse-app.yaml: Namespace warehouse-app, Deployment warehouse-api, Service warehouse-api, Certificate api-tls, HTTPProxy warehouse-api, ConfigMap warehouse-frontend-html, Deployment warehouse-frontend, Service warehouse-frontend, Certificate app-tls, and HTTPProxy warehouse-frontend.
Where Commands Run
The build crosses five execution contexts. Keep those separate and the whole example becomes much easier to reason about.
vCenter or Supervisor administration: platform administrator actions register shared services and make VM Service, package, DNS, ingress, and CA capabilities available.
VCF Automation namespace:kubectl apply -f devenv.example.yaml creates the VMs, VM Services, and VKS cluster request in the governed namespace.
Tools VM:/home/vmware/*.sh scripts install CLIs, create VCF contexts, apply the cluster, install packages, deploy the app, and inspect logs.
VKS guest cluster: app and add-on resources run warehouse-app, Contour HTTPProxy, cert-manager Certificate, Services, and Deployments.
DNS and PKI: external systems delegate names, provide trust roots, and allow automated DNS or certificate reconciliation.
Repeatable work happens from the tools VM or from an approved automation runner. That is the clean VCF example: the operator path depends on a known execution context with the right identity, network path, CA trust, CLI versions, staged values, and logs. In a larger environment, the same sequence should move into GitOps or CI, with the tools VM replaced or reduced to a debug cockpit.
Prep Before The DevEnv
Before applying the DevEnv, I want the boring platform dependencies to be explicit. The YAML can create VMs, write scripts, request a VKS cluster, install packages, and deploy the app. It should not hide the fact that DNS, trust, package access, registry access, and credentials have to be prepared.
Use this as the prep checklist:
VCF Automation endpoint: the tools VM can reach https://<vcf-automation-fqdn>. Quick check: curl -I https://<vcf-automation-fqdn>.
Tenant, project, namespace: the API token can use <vcf-automation-org>, warehouse-project, and warehouse-ns. Quick check: vcf context create --type cci ....
VKS package access: the VCF package workflow can see the VKS standard package repository. Quick check: vcf package available list -n cert-manager.
Registry path: VKS nodes can pull <registry-domain>/cache/postgrest/... and <registry-domain>/cache/nginxinc/.... Quick check: curl -I https://<registry-domain>/v2/.
DNS zone:<app-domain> is delegated or hosted where ExternalDNS can update it. Quick check: dig @<dns-server-ip> SOA <app-domain>.
Trust roots: VMs and VKS nodes can trust VCF, registry, package, and app certificate paths. Quick check: update-ca-certificates and a TLS smoke test.
Certificate issuer material: cert-manager can create or use ClusterIssuer supervisor-subca. Quick check: kubectl get clusterissuer supervisor-subca.
Lab credentials: password hashes, SSH keys, DB password, code-server password, and token placeholders are replaced. Quick check: run a public-safety scan before commit.
That order matters. DNS zone readiness comes before DNS reconciliation. Certificate material comes before app Certificates. Package access comes before cert-manager, Contour, and ExternalDNS installation. Registry trust comes before VKS nodes can pull the app images. If those pieces are unclear, the failure later looks like “Kubernetes is broken”, even when the real issue is a missing infrastructure prerequisite.
LAB WARNING: Do not paste real API tokens, private keys, real SubCA material, or reusable passwords into a public YAML. The public example keeps placeholders so people can understand the shape without inheriting private lab state.
Infrastructure Setup
This is the part I do not want to hand-wave. The DevEnv is the application/platform handoff, but a few infrastructure rails must exist first: DNS, certificates, ingress, package access, and registry trust.
DNS For ExternalDNS
DNS is where platform work often falls back to tickets. In this example, the endpoint names are declared and reconciled instead:
The same idea is used for app.<app-domain>, api.<app-domain>, db.<app-domain>, and code.<app-domain>. ExternalDNS watches Services, Ingresses, and Contour HTTPProxy resources, then reconciles records into the configured zone.
First verify that the zone exists and that you are talking to the DNS server you expect:
DNS_SERVER=<dns-server-ip>
ZONE=<app-domain>
dig @"${DNS_SERVER}" SOA "${ZONE}"
dig @"${DNS_SERVER}" NS "${ZONE}"
Then run a plain RFC2136 smoke test before you ask ExternalDNS to reconcile real platform records:
DNS_SERVER=<dns-server-ip>
ZONE=<app-domain>
TEST_NAME=externaldns-smoke
TEST_IP=<temporary-test-ip>
cat > /tmp/warehouse-rfc2136-smoke.nsupdate <<EOF
server ${DNS_SERVER}
zone ${ZONE}.
update delete ${TEST_NAME}.${ZONE}. A
update add ${TEST_NAME}.${ZONE}. 60 A ${TEST_IP}
send
EOF
nsupdate -v /tmp/warehouse-rfc2136-smoke.nsupdate
dig @"${DNS_SERVER}" +short "${TEST_NAME}.${ZONE}"
Clean up the smoke record afterwards:
cat > /tmp/warehouse-rfc2136-cleanup.nsupdate <<EOF
server ${DNS_SERVER}
zone ${ZONE}.
update delete ${TEST_NAME}.${ZONE}. A
send
EOF
nsupdate -v /tmp/warehouse-rfc2136-cleanup.nsupdate
dig @"${DNS_SERVER}" +short "${TEST_NAME}.${ZONE}"
LAB-ONLY / insecure: The smoke test above mirrors the sample --rfc2136-insecure posture. It proves mechanics in an isolated lab. It is not a production DNS security model.
For a production-like RFC2136 path, make authentication explicit:
LAB-ONLY / insecure:NonsecureAndSecure is a lab shortcut. For production, use secure dynamic updates or a DNS provider integration with scoped credentials, and let ExternalDNS hold only the minimum permission it needs for the delegated zone.
The ExternalDNS values in the DevEnv then make the controller behavior explicit:
--source=service is why LoadBalancer Services such as warehouse-db and warehouse-tools-code can publish names. --source=contour-httpproxy is what makes the HTTP routing model fit the same DNS loop. The TXT registry gives ExternalDNS ownership tracking so automated DNS does not become a shared-zone mess.
Certificates For cert-manager
The certificate story has three layers.
First, the VMs receive OS trust roots under /usr/local/share/ca-certificates/ and run update-ca-certificates. That is for outbound trust from scripts and CLIs.
Second, the VKS cluster receives CA material through osConfiguration.trust.additionalTrustedCAs. That is for node-level trust, especially when images or platform endpoints use internal certificates.
Third, cert-manager gets a SubCA through a Kubernetes TLS Secret and exposes it as ClusterIssuer supervisor-subca. That is what the app Certificates use.
LAB WARNING: The private key behind tls.key is sensitive. In a serious environment, do not commit it to Git and do not leave it in a public DevEnv. Use a secret manager, a sealed secret workflow, a platform CA integration, or a short-lived lab SubCA that can be thrown away.
The DevEnv also supports the raw PEM path. If /opt/warehouse-platform/certs/k8s-subca-fullchain.pem and /opt/warehouse-platform/certs/k8s-subca.key are present, the package script can create the Secret without hand-writing base64:
That small test answers an important question before you debug the app: can the platform issuer create a usable TLS Secret in the workload namespace?
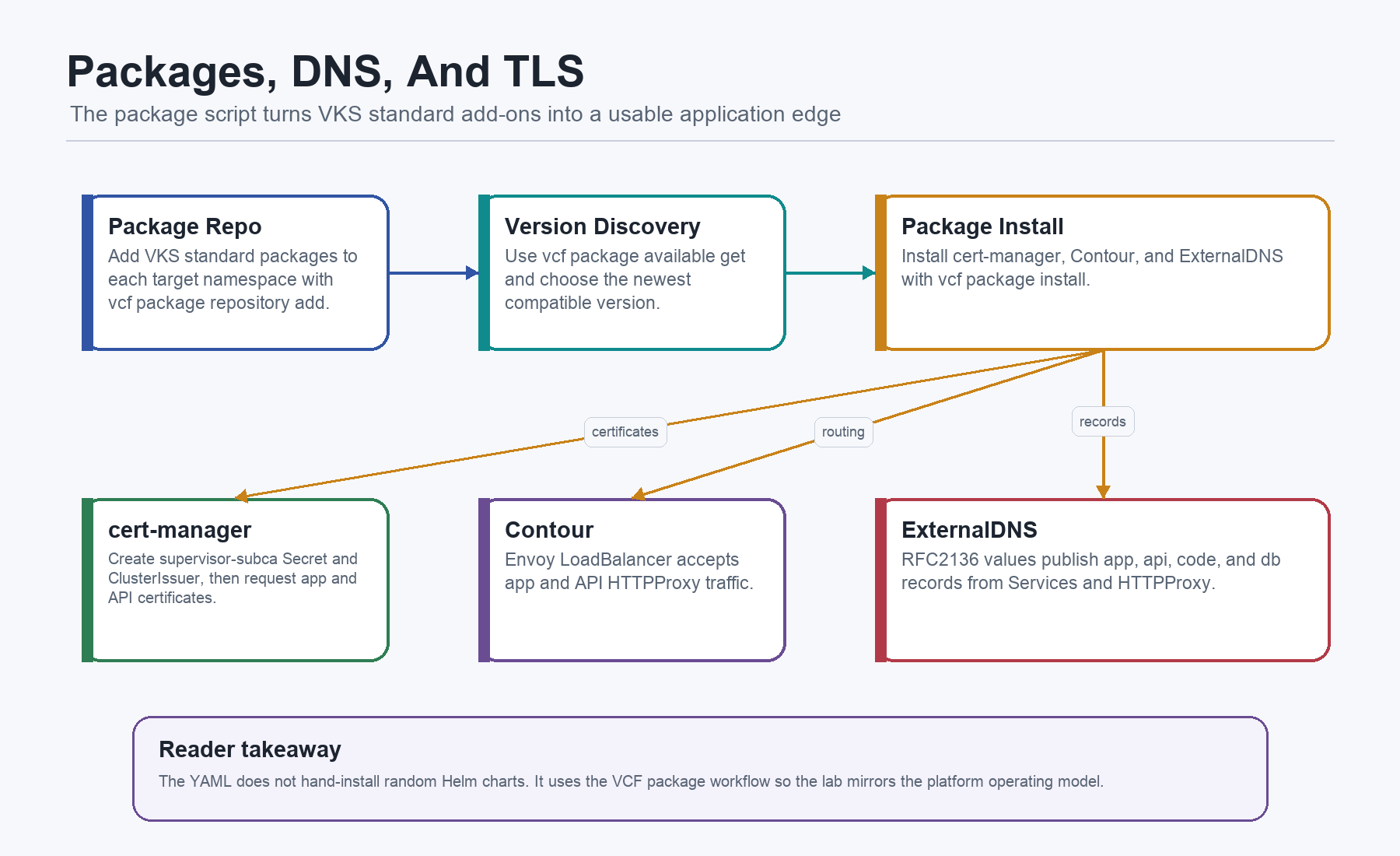
Contour, ExternalDNS, And Package Access
The current public DevEnv installs cert-manager, Contour, and ExternalDNS through the VCF package workflow. The operating model is still infrastructure-first:
cert-manager must exist before app Certificate resources can become Ready.
ClusterIssuer supervisor-subca must exist before api-tls, app-tls, or code-tls can be issued.
Contour and Envoy must exist before HTTPProxy routes can carry traffic.
ExternalDNS must be configured before declared hostnames become real DNS records.
The VKS package repository must be reachable before any of those add-ons install cleanly.
That is why /home/vmware/20-install-platform-packages.sh comes before /home/vmware/40-deploy-app.sh. The sequence is not arbitrary. It is the difference between deploying workloads into a prepared platform and asking an app manifest to bootstrap the platform around itself.
The Operator Runbook
The happy path is short:
# From the VCF Automation namespace context
kubectl -n warehouse-ns apply -f devenv.example.yaml
kubectl -n warehouse-ns get virtualmachines
kubectl -n warehouse-ns get virtualmachineservices
# After warehouse-tools is reachable
ssh vmware@code.<app-domain>
# On the tools VM
/home/vmware/10-create-cluster.sh
/home/vmware/20-install-platform-packages.sh
/home/vmware/40-deploy-app.sh
# Optional, if you want browser IDE access on code.<app-domain>
/opt/warehouse-platform/scripts/install-coder.sh
Those paths are current. The DevEnv writes the manual operator scripts into /home/vmware/ and uses /opt/bootstrap.auto.d/ only for automatic VM bootstrap.
Secret And Cloud Init
The first object is intentionally boring and important:
The two VMs use that secret for the vmware and root lab accounts. This is not a production login model. It is a lab convenience so the example is reproducible. In production, this becomes key-only SSH, scoped identities, no root login, and no password login.
The tools VM then writes several categories of files:
SSH policy:/etc/ssh/sshd_config.d/90-password.conf gives the lab VM reproducible reachability.
VCF token placeholder:/etc/vcf-api-token is the local file read by the context scripts.
Shell defaults:/etc/profile.d/10-xdg.sh keeps config and cache paths stable.
kubectl usability:/etc/profile.d/20-kubectl-alias.sh adds the k alias and completion in login shells.
Token exports:/etc/profile.d/30-vcfa-token.sh exports VCFA_TOKEN and KUBECTL_VCFA_TOKEN.
CA trust:/usr/local/share/ca-certificates/*.crt installs internal CA material before CLI calls.
Auto bootstrap:/home/vmware/bootstrap.sh and /opt/bootstrap.auto.d/00-tools-setup.sh install tooling and select the base context.
Manual scripts:/home/vmware/10-create-cluster.sh, /home/vmware/20-install-platform-packages.sh, and /home/vmware/40-deploy-app.sh are the ordered operator flow.
Platform bundle:/opt/warehouse-platform/... holds values, cluster YAML, app YAML, certificates, and the optional code-server installer.
That is the pattern I like: one declared environment, but the generated machine is still inspectable. You can SSH in, read the scripts, tail the bootstrap logs, and understand what happened.
Installing kubectl And VCF CLI
Broadcom’s VCF CLI documentation says the VCF CLI is the command-line interface for VCF Automation and Supervisor environments, and that kubectl is required for Kubernetes operations. The docs list browser download paths through the VCF Automation tenant portal, the Supervisor home page, and the Broadcom Support portal. The lab automates Linux installation from the Broadcom package repository so cloud-init can do it without a browser.
The tools VM installs base packages, then fetches kubectl:
This is why the tools VM is worth having. It is not just a jump host. It becomes the controlled execution environment where the CLI versions, shell behavior, trust store, contexts, and logs are reproducible.
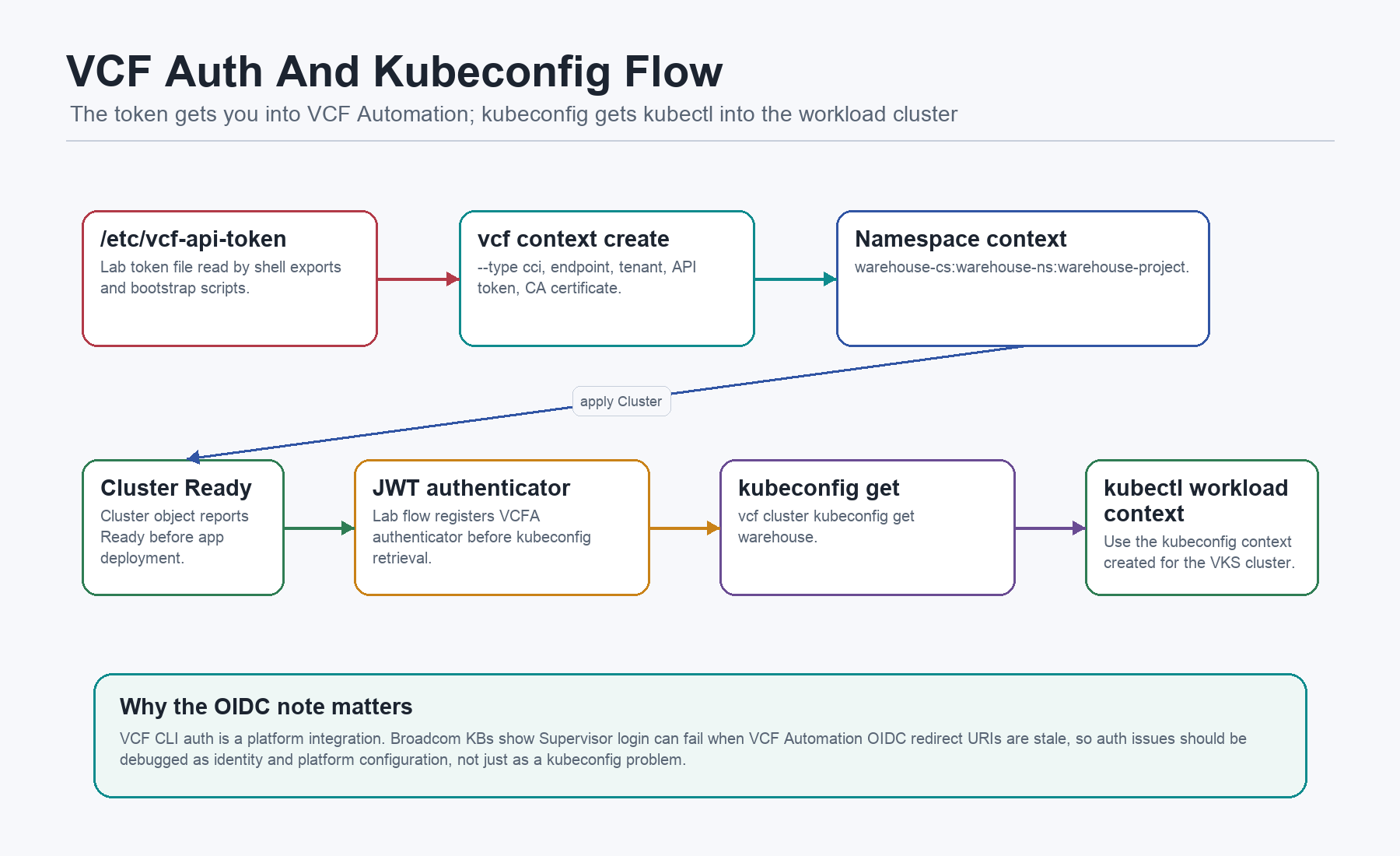
VCF Contexts And Kubeconfig
VCF CLI contexts are the bridge between the operator VM and VCF Automation. Broadcom’s quick start describes a cci context for VCF Automation using an API token, and then switching into a namespace or project context for cluster work.
The auto bootstrap creates the base VCF Automation context:
/home/vmware/10-create-cluster.sh repeats the context setup idempotently, applies the VKS cluster manifest, waits for readiness, and then retrieves a kubeconfig:
kubectl apply -n "${NS}" -f "/opt/warehouse-platform/k8s/cluster-warehouse.yaml"
# The script waits up to 90 minutes and prints phase, control-plane and worker readiness.
vcf cluster register-vcfa-jwt-authenticator "${CLUSTER}" || true
vcf cluster kubeconfig get "${CLUSTER}" || true
CTX=$(kubectl config get-contexts -o name \
| grep -E "^vcf-cli-${CLUSTER}-${NS}@${CLUSTER}-${NS}$" || true)
kubectl config use-context "${CTX}"
The JWT authenticator line deserves a plain explanation. The lab uses it so the retrieved workload kubeconfig can authenticate through the VCF Automation path. The public VCF CLI quick start documents API-token CCI contexts and vcf cluster kubeconfig get. Broadcom KBs also show that Supervisor login through VCF CLI depends on healthy VCF Automation and OIDC redirect configuration. So if this breaks, do not debug it as “just a kubeconfig file”. Check the identity path, the VCF Automation org, the Supervisor identity provider, and the redirect URIs.
The VKS Cluster Request
The cluster manifest is a Cluster API object. That matters because VKS is not inventing a random YAML dialect. The official VKS API docs describe VKS as a declarative Cluster API based way to define cluster topology, node pools, VM classes, storage policies, and networking.
The current DevEnv writes this to /opt/warehouse-platform/k8s/cluster-warehouse.yaml:
clusterNetwork: pod CIDR, Service CIDR, and service domain for the guest cluster.
topology.class: the ClusterClass selected from the platform.
classNamespace: where the public VKS ClusterClass lives.
version: VKS Kubernetes release version.
variables.kubernetes: cluster-level Kubernetes behavior such as certificate rotation.
variables.vmClass: default VM class for nodes.
variables.storageClass: storage class for node disks.
variables.osConfiguration.trust.additionalTrustedCAs: CA material trusted by nodes, useful when images come from an internal registry.
controlPlane.replicas: three control-plane nodes in the lab.
workers.machineDeployments: one worker pool in zone01 with three replicas.
The VKS variable docs are useful here because they explain the hierarchy. Cluster-level variables set defaults. Control-plane and worker-pool variables can override them. In this lab, the defaults are enough, but the shape is ready for per-pool specialization later.
VCF Package Installation
This was missing too much detail before. The current file does not install Contour and ExternalDNS with random Helm commands. It uses the VCF package workflow against a VKS standard package repository.
The package installer lives at /home/vmware/20-install-platform-packages.sh. It adds the VKS standard package repository to the target namespaces, discovers package versions, and installs the packages:
REPO_NAME="2025.10.22"
REPO_URL="projects.packages.broadcom.com/vsphere/supervisor/packages/2025.10.22/vks-standard-packages:3.5.0-20251022"
ensure_repo() {
local ns="$1"
if ! vcf package repository list -n "$ns" 2>/dev/null | grep -qw "$REPO_NAME"; then
vcf package repository add "$REPO_NAME" --url "$REPO_URL" -n "$ns"
fi
}
latest_ver() {
vcf package available get "$1" -n "$2" 2>/dev/null \
| awk '/^[[:space:]]*[0-9]+\.[0-9]+\./{print $1}' \
| sort -Vr \
| head -1
}
ensure_ns creates the target namespace if it does not exist, so the package install can be repeated without a separate namespace prep step.
ensure_repo adds the VKS standard package repository to that namespace, keeping package discovery inside the VCF package model instead of a hidden Helm repo.
latest_ver reads available versions for a package and picks the newest visible version. That is useful in a lab; production should pin this.
install_pkg checks whether the package is already installed and then calls vcf package install, which makes the script rerunnable.
The ExternalDNS namespace label sets pod-security.kubernetes.io/enforce=privileged for the lab package defaults. In production, validate this against your Pod Security posture.
Rollout and list checks wait for cert-manager deployments and print installed packages across namespaces, giving the operator a real checkpoint before app deployment.
Broadcom examples use the same family of commands: add a VKS standard package repo, inspect available packages, run vcf package install, and list installed packages. The Broadcom package KBs and VKS package examples are also why the article now uses the *.kubernetes.vmware.com package names instead of older Tanzu-era names.
If your installed vcf binary does not expose package subcommands, check the plugin first:
vcf plugin install package
vcf package available list -n tkg-system
In the lab script, version discovery is dynamic so the example tracks what the repository exposes. In production I would normally pin versions deliberately and move the package repository URL and versions into configuration.
Certificates And Trust
The DevEnv handles trust in three layers.
First, the VM operating systems receive CA files under /usr/local/share/ca-certificates/ and run update-ca-certificates. That helps CLI tools trust internal endpoints.
Second, the VKS cluster receives CA material through osConfiguration.trust.additionalTrustedCAs. That is what lets nodes trust internal registry or platform certificates.
Third, cert-manager receives a SubCA as a Kubernetes TLS Secret and a ClusterIssuer:
That distinction matters. A Kubernetes TLS Secret uses tls.crt and tls.key. Other Supervisor Service or platform configuration screens may use different field names. When a reader mixes those contexts, certificates become confusing very quickly.
The app uses the same issuer for api.<app-domain> and app.<app-domain>, and the optional code-server path uses the same CA material for code.<app-domain>.
DNS And Contour Values
ExternalDNS is configured for an RFC2136 lab zone. The important part is not the exact DNS provider. The important part is that the app expresses hostnames declaratively and the platform reconciles records.
--source=service allows records for LoadBalancer Services such as warehouse-tools-code and warehouse-db. --source=contour-httpproxy allows records for Contour HTTPProxy objects such as the app and API routes. The TXT registry gives ownership tracking so automation does not blindly overwrite shared DNS records.
The lab uses --rfc2136-insecure for simplicity. Do not treat that as a production recommendation. Use authenticated DNS updates, a delegated zone, restricted keys, and a narrow domain filter.
Contour is installed with Envoy as a LoadBalancer:
Contour gives the app a clean HTTP routing contract. ExternalDNS gives the routes names. cert-manager gives them certificates. The app team should not need to open three tickets to make a simple HTTPS endpoint exist.
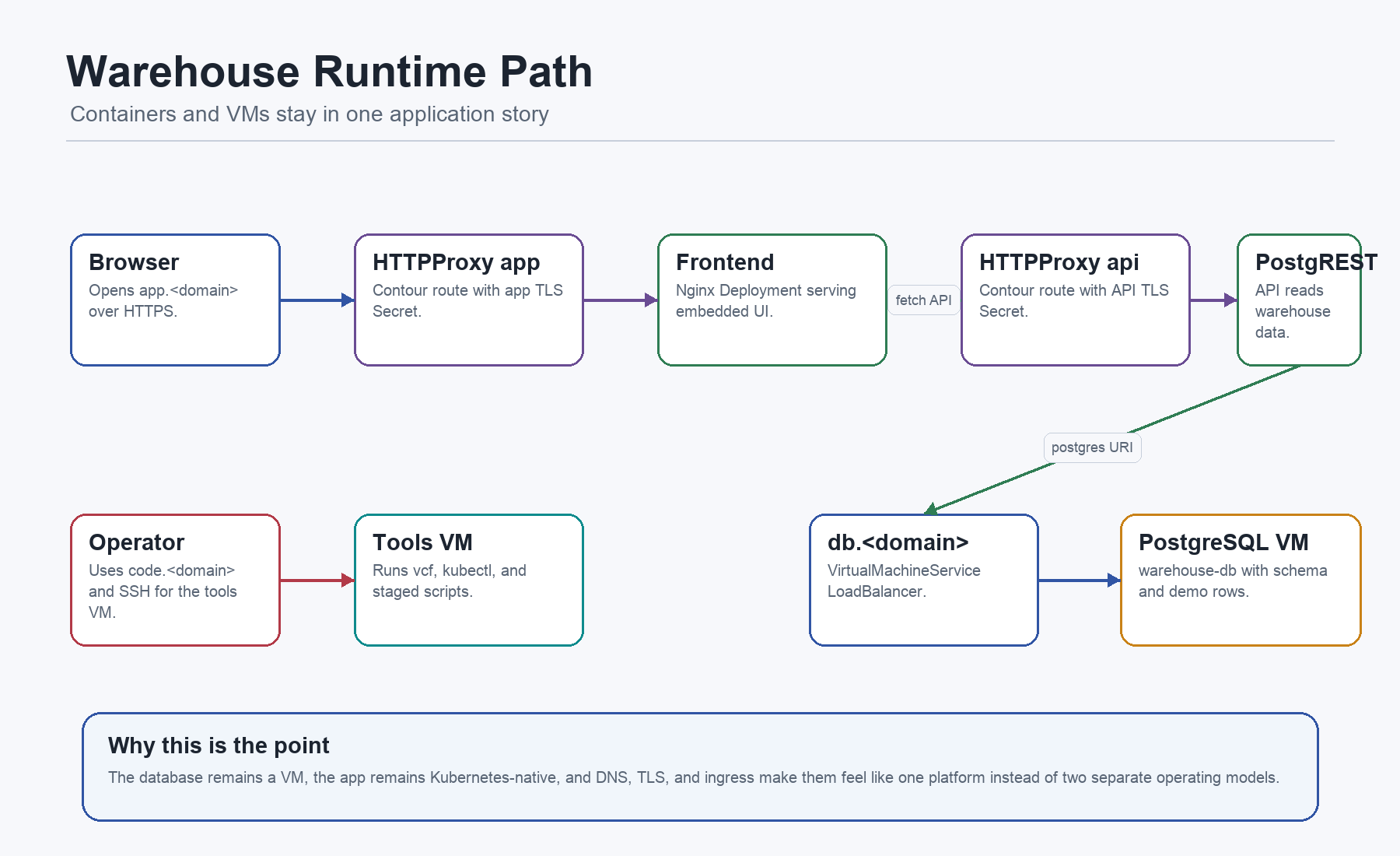
The App Bundle
The runtime path is mixed on purpose. The frontend and API are Kubernetes-native. The database remains a VM. VM Service makes that feel like one platform.
/opt/warehouse-platform/k8s/warehouse-app.yaml contains ten objects:
Namespace warehouse-app: holds the app tier.
Deployment warehouse-api: runs PostgREST.
Service warehouse-api: exposes the API internally on Service port 80.
Certificate api-tls: requests TLS for api.<app-domain>.
HTTPProxy warehouse-api: routes HTTPS traffic to the API Service.
ConfigMap warehouse-frontend-html: embeds the small demo frontend.
Deployment warehouse-frontend: runs unprivileged nginx on port 8080.
Service warehouse-frontend: exposes the frontend internally on Service port 80.
Certificate app-tls: requests TLS for app.<app-domain>.
HTTPProxy warehouse-frontend: routes HTTPS traffic to the frontend Service.
The app manifest is easiest to read as two internal workloads and two edge routes.
The API workload is deliberately small. It runs PostgREST, which turns the PostgreSQL schema into an HTTP API:
image: pulls PostgREST from the internal registry cache. The VKS nodes need CA trust for that path.
securityContext: runs as non-root, blocks privilege escalation, drops capabilities, and uses the runtime default seccomp profile.
PGRST_DB_URI: connects to PostgreSQL through db.<app-domain>, which is backed by the DB VirtualMachineService.
PGRST_DB_SCHEMAS: exposes the public schema.
PGRST_DB_ANON_ROLE: uses the acme PostgreSQL role that the DB bootstrap grants read access to.
PGRST_SERVER_PORT: makes the container listen on port 3000.
For a lab, the DB URI is visible so the reader can understand the path. For production, it becomes a Secret or an external secret reference. The architectural contract stays the same: the API reaches PostgreSQL by the platform-owned name db.<app-domain>.
The API Service is the internal contract for that container:
That targetPort is the handoff from Kubernetes networking to the container. Contour does not talk to the pod port directly. It routes to the Service on port 80, and the Service forwards to the PostgREST container on 3000.
The API edge is then made of two objects: cert-manager requests a certificate, and Contour consumes the certificate in an HTTPProxy route.
That one line explains the browser path. A user opens https://app.<app-domain>. The frontend JavaScript then fetches inventory rows from https://api.<app-domain>/products. If the browser shows the page but no products, you debug the API route, cert, CORS behavior, DNS, and database path, not the nginx container first.
The frontend container is unprivileged nginx serving that ConfigMap as static content:
That is the app layer end to end: ConfigMap becomes static frontend, nginx serves it, PostgREST exposes database rows, Services give stable in-cluster names, Certificates create TLS Secrets, and HTTPProxy objects make both endpoints reachable through Contour.
VM Service As The Bridge
The VM Operator docs describe a VirtualMachine as the desired state for a vSphere VM, with fields such as className, imageName, storageClass, and bootstrap.cloudInit. That is exactly what the DevEnv uses.
This is the architectural point of the example. PostgreSQL does not have to be containerized for the platform to manage its reachability. VM Service exposes a VM-shaped dependency with Kubernetes-style intent, and ExternalDNS can publish the resulting name.
The current public example exposes a single warehouse-tools-code service for both HTTPS and SSH.
The Database Bootstrap
The DB side is not just “a VM with Postgres”. It is a small backing-service design with four parts:
VirtualMachine warehouse-db in the VCF Automation namespace provides the Ubuntu VM, VM class, storage class, labels, cloud-init, and bootstrap scripts.
PostgreSQL bootstrap on the DB VM creates the role, database, table, rows, and grants for PostgREST.
Remote lab access on the DB VM enables listen_addresses='*', pg_hba.conf, and optional firewall opening for port 5432.
VirtualMachineService warehouse-db in the VCF Automation namespace provides the LoadBalancer and ExternalDNS hostname db.<app-domain>.
00-vcf-bootstrap.sh installs VCF CLI, kubectl, completion, optional helpers such as kubectx and k9s, and creates the same VCF Automation context shape as the tools VM. The DB VM is not supposed to become the main operator workstation. The point is that, during a lab, the VM can still inspect its surrounding platform context and produce useful diagnostics.
10-db-setup.sh installs PostgreSQL, creates the acme role, creates the acme_warehouse database, and writes demo rows:
The schema is intentionally tiny because the article is about platform plumbing, not inventory software:
CREATE TABLE IF NOT EXISTS products(
id SERIAL PRIMARY KEY,
name TEXT,
sku TEXT,
stock INT,
location TEXT,
image TEXT
);
INSERT INTO products(name, sku, stock, location, image) VALUES
('Forklift Model Z', 'FL-Z-100', 10, 'Bay A1', 'https://placehold.co/320x200?text=Forklift'),
('Barcode Scanner X5', 'BC-X5-200', 25, 'Bay B3', 'https://placehold.co/320x200?text=Scanner'),
('Smart Shelf Controller', 'SSC-700', 5, 'Bay C2', 'https://placehold.co/320x200?text=Controller');
The grants are the part many examples forget. PostgREST does not become useful just because the TCP path works. The database role has to be allowed to connect, use the schema, read the tables, and read sequences:
GRANT CONNECT ON DATABASE acme_warehouse TO acme;
GRANT USAGE ON SCHEMA public TO acme;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO acme;
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO acme;
GRANT USAGE, SELECT ON ALL SEQUENCES IN SCHEMA public TO acme;
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT USAGE, SELECT ON SEQUENCES TO acme;
That is what makes this API environment functional. The PostgREST container uses PGRST_DB_ANON_ROLE=acme; the DB bootstrap gives acme enough read access to serve /products.
15-db-remote-access.sh makes PostgreSQL listen on all interfaces and allows remote connections:
sudo sed -ri "s/^[#[:space:]]*listen_addresses[[:space:]]*=.*/listen_addresses = '*'/" "$PG_CONF_FILE"
cat >> "$PG_HBA_FILE" <<'EOF'
host all all 0.0.0.0/0 scram-sha-256
host all all ::/0 scram-sha-256
EOF
The VirtualMachineService warehouse-db then exposes that port as a platform object:
That is deliberately flagged as lab-only. It makes the example easy to test, but production should restrict source networks, use proper secrets, remove broad SSH exposure, and put database reachability behind a tighter policy. The teaching point still holds: a VM-backed service can be declared, named, and consumed by a Kubernetes-native API without pretending the database is a pod.
Optional Code Surface
The tools VM carries an optional code-server installer:
/opt/warehouse-platform/scripts/install-coder.sh
It installs code-server, creates a coder user, generates a TLS certificate for code.<app-domain> from the local SubCA material, and runs code-server on port 443 with systemd. The matching warehouse-tools-code service exposes that port.
This is useful in a lab because it gives you a browser IDE inside the same network and identity context as the platform tooling. In production I would treat it like any other admin surface: SSO or strong auth, short-lived access, restricted network path, and a disposable host or runner model.
What Must Exist Outside The YAML
The file is powerful, but it is not a universe in a bottle. A few things must already be true in the environment:
<vcf-automation-fqdn>: reachable VCF Automation endpoint for the vcf context create --type cci flow.
<vcf-automation-org>, project, and namespace: tenant, project, and namespace names that the API token can use.
<registry-domain>: registry or registry cache that serves PostgREST and nginx-unprivileged images.
<app-domain>: DNS zone where app, api, db, and code names can be created.
<dns-server-ip>: RFC2136-capable DNS target for ExternalDNS in the lab.
CA placeholders: trust roots for VCF Automation, registry access, package access, and SubCA signing.
<db-password> and <code-server-password>: lab credentials. Replace with proper secrets before any serious use.
SSH public key and password hashes: lab operator access to the tools and DB VMs.
This is also why the example is structured as generated files on VMs instead of a pile of copy-paste commands. Once the placeholders are filled, the reader can apply the DevEnv, SSH to the tools VM, and run the three operator scripts in order. The missing state is explicit instead of being hidden in someone’s shell history.
What Is Lab-Only
The public file is useful because it is functional. It is not a production baseline. The file itself flags the risky parts, and the article should do the same.
PRODUCTION: The architecture can stay. The lab shortcuts disappear.
Password login and root login: useful for reproducible lab reachability; production should use key-only SSH, no root login, federated access, and an audited bastion or runner.
/etc/vcf-api-token: useful for non-interactive VCF CLI context creation; production should use a secret manager, scoped token, short lifetime, and rotation.
Placeholder CA material: useful to show every trust path; production should use real PKI, verified chains, and never commit private keys.
RFC2136 insecure mode: useful for quick DNS automation in a lab; production should use authenticated DNS updates with scoped keys and delegated zones.
Windows DNS NonsecureAndSecure: useful for fast isolated validation; production should use secure dynamic updates or scoped DNS provider credentials.
Broad PostgreSQL access: useful to make the API path obvious; production should use network policy, service-local reachability, and restricted CIDRs.
pg_hba.conf allowing all networks: useful to remove network guesswork in a first lab; production should use explicit source CIDRs, private reachability, firewall policy, and audited DB access.
Dynamic package version selection: useful for lab bootstrapping; production should pin versions and promote them through tested upgrade windows.
Inline DB URI: useful because the data path is readable; production should use a Kubernetes Secret, external secret, or workload identity integration.
Inline SubCA Secret or raw private key files: useful to show the cert-manager flow end to end; production should use a secret manager, sealed secret, CA integration, or one-time injected secret material.
Optional code-server on code.<app-domain>: useful as a browser IDE in the lab context; production should use a short-lived runner, SSO, restricted network path, strong auth, and a disposable host.
The pattern still matters. A production version does not throw the design away. It hardens the identities, secrets, networks, and version pinning while preserving the useful contract: one declared environment, repeatable platform contexts, package-managed add-ons, DNS and TLS reconciliation, VM Service for VM dependencies, and a small app that proves the path.
In a productionized version I would keep the same architecture and change the implementation discipline:
secrets come from a secret store instead of inline bootstrap content
VCF authentication avoids long-lived local token files
VM access is key-based, scoped, and audited
database credentials are generated, rotated, and injected as Secrets
certificates are issued through approved ClusterIssuer contracts
DNS updates use authenticated provider integration
package versions are pinned and promoted through tested environments
registry access is private, trusted, and observable
workload namespaces get policy, quota, ownership, and lifecycle rules
That is the intended evolution: exercise the platform flow first, then harden the same model instead of changing the mental map after the demo works.
Why This Matters
The interesting part of VKS is not that it can run pods. The interesting part is that VCF can make Kubernetes, VMs, DNS, certificates, and package-managed add-ons behave like one platform.
Warehouse is small, but it forces the important questions:
Can an app team get a cluster without a bespoke infrastructure conversation?
Can a VM-backed service be consumed by a Kubernetes app without manual glue?
Can the platform create DNS records and certificates from declared intent?
Can package installation be done through the VCF operating model instead of ad hoc scripts?
Can a new operator understand where every command runs?
When the answer is yes, the platform starts feeling like a product instead of a collection of parts.
Sources Checked
I checked the current public Broadcom and VMware documentation while updating the article:
Partially AI-modified / AI transparency: This publication is AI-assisted and human-reviewed. Constantin Korte assumes editorial responsibility. See AI Transparency.
TL;DR
If VKS tokens keep expiring, this PowerShell helper refreshes saved VCF CLI contexts so you stop logging into every supervisor by hand.
If you use many VKS supervisors, your access tokens expire quickly and you end up logging in to every cluster again. The VCF CLI can handle this for you. The following PowerShell script walks through every saved context and refreshes the tokens automatically.
<#
.SYNOPSIS
Refresh (and if needed re-auth) all VCF CLI contexts non-interactively.
.NOTES
- No TMC special-casing here; treats all contexts the same.
- Fixes the bug where $Args conflicted with PowerShell’s automatic $args.
.PARAMETER Password
SecureString password for this run (no storage).
.PARAMETER PromptForPassword
Prompt for the password securely (no storage).
.PARAMETER SaveCredential
Prompt once and save password securely for reuse (DPAPI file; Credential Manager if available).
.PARAMETER UseSavedCredential
Load previously saved password (DPAPI file or Credential Manager).
.PARAMETER ClearCredential
Remove any stored credential and exit.
.PARAMETER CredTarget
Name for the stored credential (if Credential Manager is used). Default: VCF-SSO.
#>
[CmdletBinding()]
param(
[Parameter(ParameterSetName='Direct', Mandatory=$false)]
[SecureString]$Password,
[Parameter(ParameterSetName='Prompt', Mandatory=$true)]
[switch]$PromptForPassword,
[Parameter(Mandatory=$false)]
[switch]$SaveCredential,
[Parameter(Mandatory=$false)]
[switch]$UseSavedCredential,
[Parameter(Mandatory=$false)]
[switch]$ClearCredential,
[Parameter(Mandatory=$false)]
[string]$CredTarget = 'VCF-SSO'
)
# ---------- Secure storage (DPAPI; optional Windows Credential Manager) ----------
$AppDir = Join-Path $env:APPDATA 'VcfCli'
$CredFile = Join-Path $AppDir 'vcf_sso_cred.xml'
function ConvertTo-PlainText([SecureString]$Secure) {
if (-not $Secure) { return $null }
$bstr = [Runtime.InteropServices.Marshal]::SecureStringToBSTR($Secure)
try { [Runtime.InteropServices.Marshal]::PtrToStringBSTR($bstr) }
finally { [Runtime.InteropServices.Marshal]::ZeroFreeBSTR($bstr) }
}
function Save-Password([SecureString]$Secure, [string]$Target) {
if (-not (Test-Path $AppDir)) { [void](New-Item -Type Directory -Path $AppDir -Force) }
$cred = New-Object System.Management.Automation.PSCredential ('vcf', $Secure)
$cred | Export-Clixml -Path $CredFile
$cm = Get-Module -ListAvailable -Name CredentialManager | Select-Object -First 1
if ($cm) {
try {
Import-Module CredentialManager -ErrorAction Stop | Out-Null
$plain = ConvertTo-PlainText $Secure
if ($plain) { New-StoredCredential -Target $Target -UserName 'vcf' -Password $plain -Persist LocalMachine | Out-Null }
} catch { }
}
}
function Load-Password([string]$Target) {
$cm = Get-Module -ListAvailable -Name CredentialManager | Select-Object -First 1
if ($cm) {
try {
Import-Module CredentialManager -ErrorAction Stop | Out-Null
$stored = Get-StoredCredential -Target $Target
if ($stored -and $stored.Password) { return ($stored.Password | ConvertTo-SecureString -AsPlainText -Force) }
} catch { }
}
if (Test-Path $CredFile) {
try {
$cred = Import-Clixml -Path $CredFile
if ($cred -and $cred.Password) { return $cred.Password }
} catch { }
}
return $null
}
function Clear-Password([string]$Target) {
if (Test-Path $CredFile) { Remove-Item $CredFile -Force -ErrorAction SilentlyContinue }
$cm = Get-Module -ListAvailable -Name CredentialManager | Select-Object -First 1
if ($cm) {
try {
Import-Module CredentialManager -ErrorAction Stop | Out-Null
Remove-StoredCredential -Target $Target -ErrorAction SilentlyContinue
} catch { }
}
}
if ($ClearCredential) {
Clear-Password -Target $CredTarget
Write-Host "Stored credential cleared." -ForegroundColor Yellow
return
}
# ---------- Determine password ----------
$SecurePwd = $null
switch ($PSCmdlet.ParameterSetName) {
'Prompt' { $SecurePwd = Read-Host 'Enter VCF password' -AsSecureString }
'Direct' { $SecurePwd = $Password }
default {
if ($UseSavedCredential) {
$SecurePwd = Load-Password -Target $CredTarget
if (-not $SecurePwd) { throw "No saved credential found. Run with -SaveCredential or -PromptForPassword." }
} elseif ($SaveCredential) {
$SecurePwd = Read-Host 'Enter VCF password to save (hidden)' -AsSecureString
Save-Password -Secure $SecurePwd -Target $CredTarget
Write-Host "Credential saved securely." -ForegroundColor Green
} else {
$SecurePwd = Load-Password -Target $CredTarget
if (-not $SecurePwd) { $SecurePwd = Read-Host 'Enter VCF password (not stored)' -AsSecureString }
}
}
}
$PlainPwd = ConvertTo-PlainText $SecurePwd
if (-not $PlainPwd) { throw "No password available." }
# ---------- CLI wrapper (avoid $args conflict; support PS5/PS7) ----------
function Invoke-Vcf {
param([string[]]$ArgList)
# Prefer native invocation with array splatting (PS7+). For PS5, fall back to cmd.exe
if ($PSVersionTable.PSVersion.Major -ge 7) {
$out = & vcf @ArgList 2>&1
} else {
$quoted = $ArgList | ForEach-Object { if ($_ -match '[\s"]') { '"' + ($_ -replace '"','\"') + '"' } else { $_ } }
$cmd = 'vcf ' + ($quoted -join ' ')
$out = & cmd /c $cmd 2>&1
}
$code = if ($LASTEXITCODE -ne $null) { $LASTEXITCODE } else { 0 }
[pscustomobject]@{ ExitCode = $code; Output = ($out -join "`n") }
}
function Get-VcfContexts {
# Primary attempt
$res = Invoke-Vcf @('context','list')
if ($res.ExitCode -ne 0) { throw "Failed to list contexts:`n$($res.Output)" }
# If we somehow got top-level help, don’t parse it as contexts.
if ($res.Output -match 'Usage:\s+vcf\b' -or $res.Output -match 'Available command groups:') {
throw "CLI returned help text instead of contexts. Ensure 'vcf context list' works in this shell."
}
$names = @()
foreach ($line in ($res.Output -split "`n")) {
if ($line -match '^\s*$' -or $line -match '^\s*(NAME|CURRENT|\-+)\b') { continue }
# Extract the first token (context name), but only if it looks like a context (lowercase/colon/digit/._-)
if ($line -match '^\s*(?<name>[a-z0-9][a-z0-9._:-]*)\b') {
$n = $Matches['name']
if ($n -ne 'vcf' -and $n -ne 'usage') { $names += $n }
}
}
$names = $names | Sort-Object -Unique
if (-not $names) { throw "No contexts parsed from 'vcf context list'. Raw:`n$($res.Output)" }
return $names
}
function Try-Refresh([string]$ctx) { Invoke-Vcf @('context','refresh', $ctx) }
# ---------- Main ----------
Write-Host "Collecting contexts..." -ForegroundColor Cyan
$contexts = Get-VcfContexts
$env:VCF_CLI_VSPHERE_PASSWORD = $PlainPwd # non-interactive auth for Supervisor/VKS
$failed = @()
try {
Write-Host "Found contexts:" -ForegroundColor Cyan
$contexts | ForEach-Object { Write-Host " - $_" }
foreach ($ctx in $contexts) {
Write-Host "`n[$ctx] Refresh..." -ForegroundColor Yellow
$r = Try-Refresh $ctx
if ($r.ExitCode -eq 0) {
Write-Host "[$ctx] OK (refreshed or token still valid)." -ForegroundColor Green
continue
}
Write-Warning "[$ctx] refresh failed (ExitCode=$($r.ExitCode)). Trying 'use'..."
$u = Invoke-Vcf @('context','use', $ctx)
if ($u.ExitCode -eq 0) {
Write-Host "[$ctx] Re-auth via 'use' OK." -ForegroundColor Green
$r2 = Try-Refresh $ctx
if ($r2.ExitCode -eq 0) { Write-Host "[$ctx] Final refresh OK." -ForegroundColor Green }
} else {
Write-Host "[$ctx] Could not re-auth without an interactive terminal. Check endpoint trust/credentials." -ForegroundColor Red
$failed += $ctx
}
}
}
finally {
$env:VCF_CLI_VSPHERE_PASSWORD = $null
$PlainPwd = $null
}
if ($failed.Count) {
Write-Host "`nManual follow-up required for:" -ForegroundColor Magenta
$failed | ForEach-Object { Write-Host " - $_" }
}
Why this script is handy
no typing for each cluster
enter the password once or store it securely for reuse
cleans up the environment after running
suitable for lab setups and production installations
Partially AI-modified / AI transparency: This publication is AI-assisted and human-reviewed. Constantin Korte assumes editorial responsibility. See AI Transparency.
TL;DR
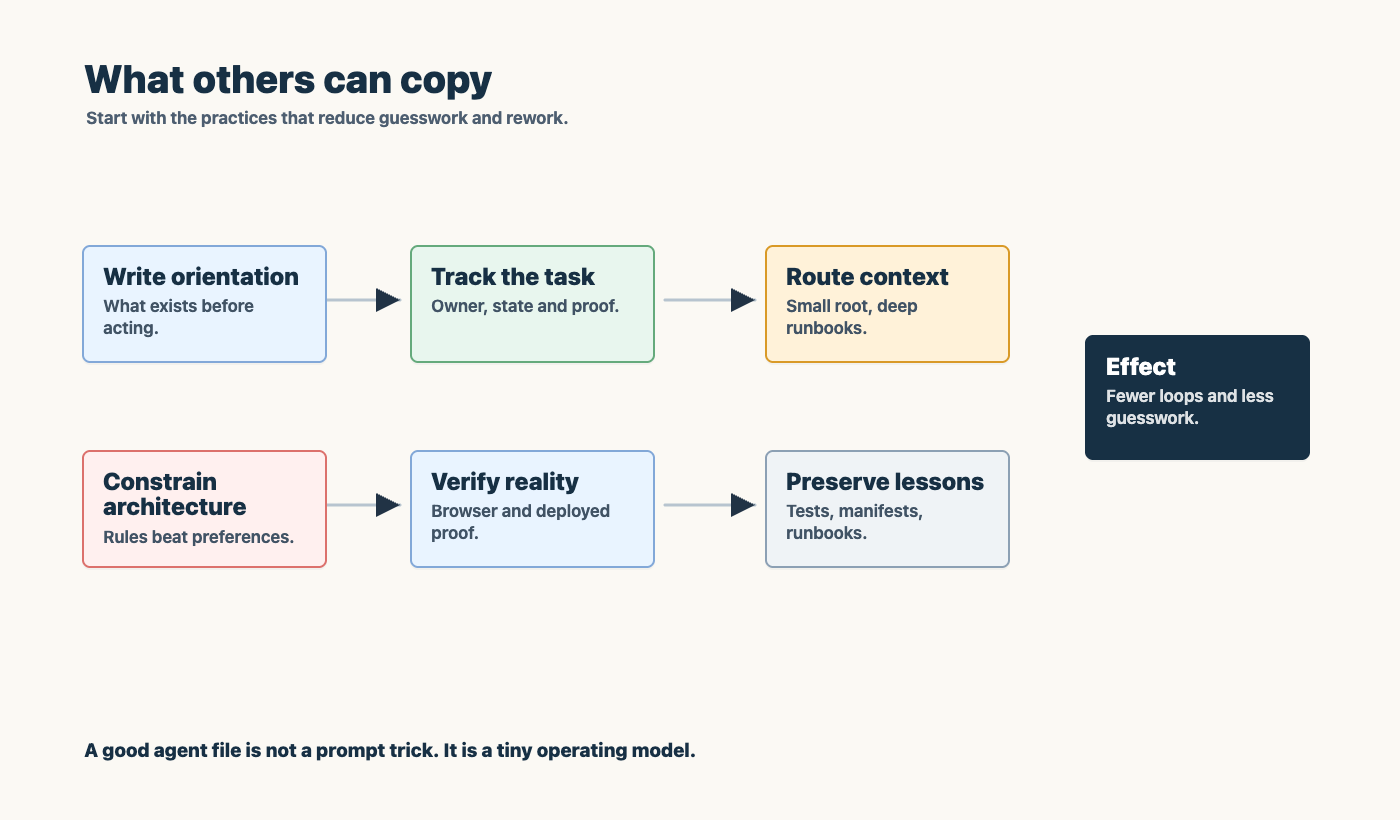
Good agentic engineering is not a prompt trick. It is a workspace contract: scope, tools, backlog, pipeline, tests, browser proof, and one deployable source of truth.
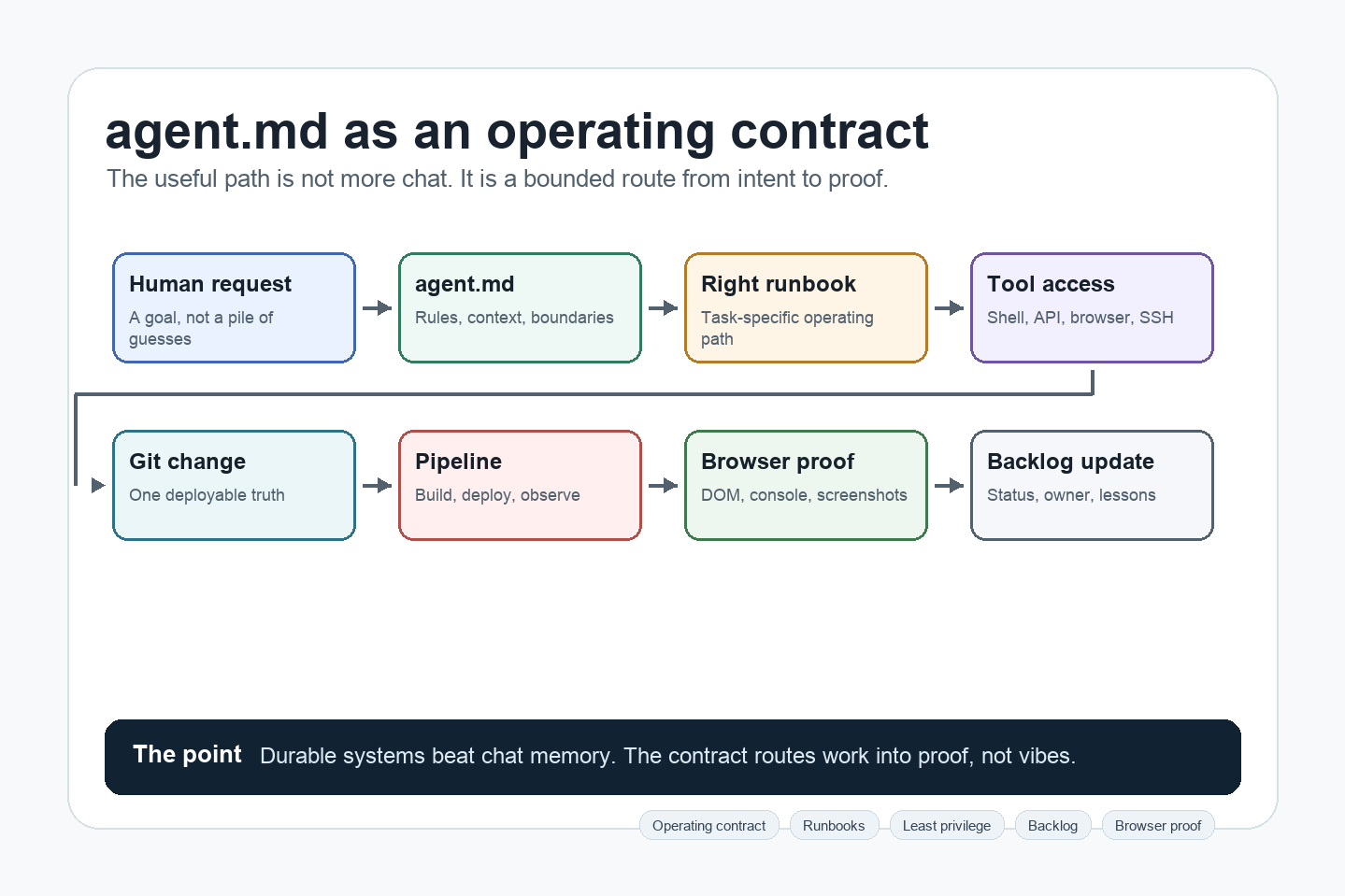
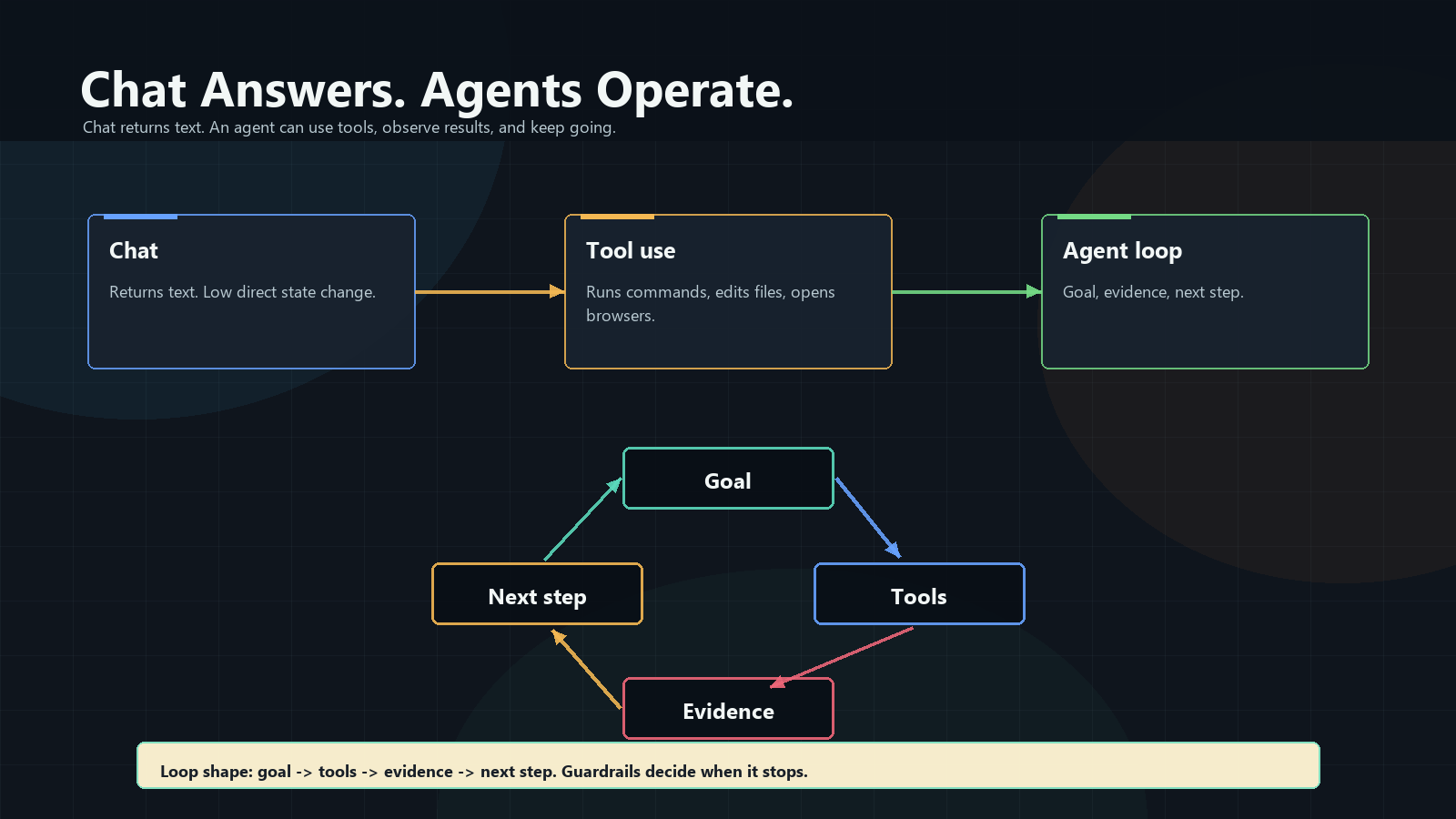
When people hear “agentic AI”, they often imagine a smarter chat window. That is too small. In real engineering work, the agent sits inside a workspace: a Git repository with source code, scripts, documentation, and sometimes controlled access to tools like a terminal, APIs, a browser testing tool, or a deployment pipeline.
By agentic engineering I mean engineering work where an AI agent can answer, inspect, change, run, verify, and report inside a bounded workspace.
AGENTS.md is an open Markdown convention for guiding coding agents. The easiest way to think about it is this: it is a README for the agent. A README helps a human understand the project. An AGENTS.md or agent.md helps the agent understand how it is allowed to work.
In my projects, that file does more than list commands. It explains where the truth lives, how work enters the backlog, which runbooks matter, what systems may be touched, what is off-limits, and what proof is required before anything is called done.
That is the important move. Good agentic work is not primarily about one clever prompt. It is about giving the agent a real operating model, then forcing the work to pass through evidence: Git changes, pipeline runs, browser checks, logs, tests, and backlog updates.
So yes, many teams now have an AGENTS.md or agent.md. The difference is how seriously it is treated. For me, it is not a preferences file. It is the operating contract for the work.
The prompt still matters, but the working environment matters more.
The real problem
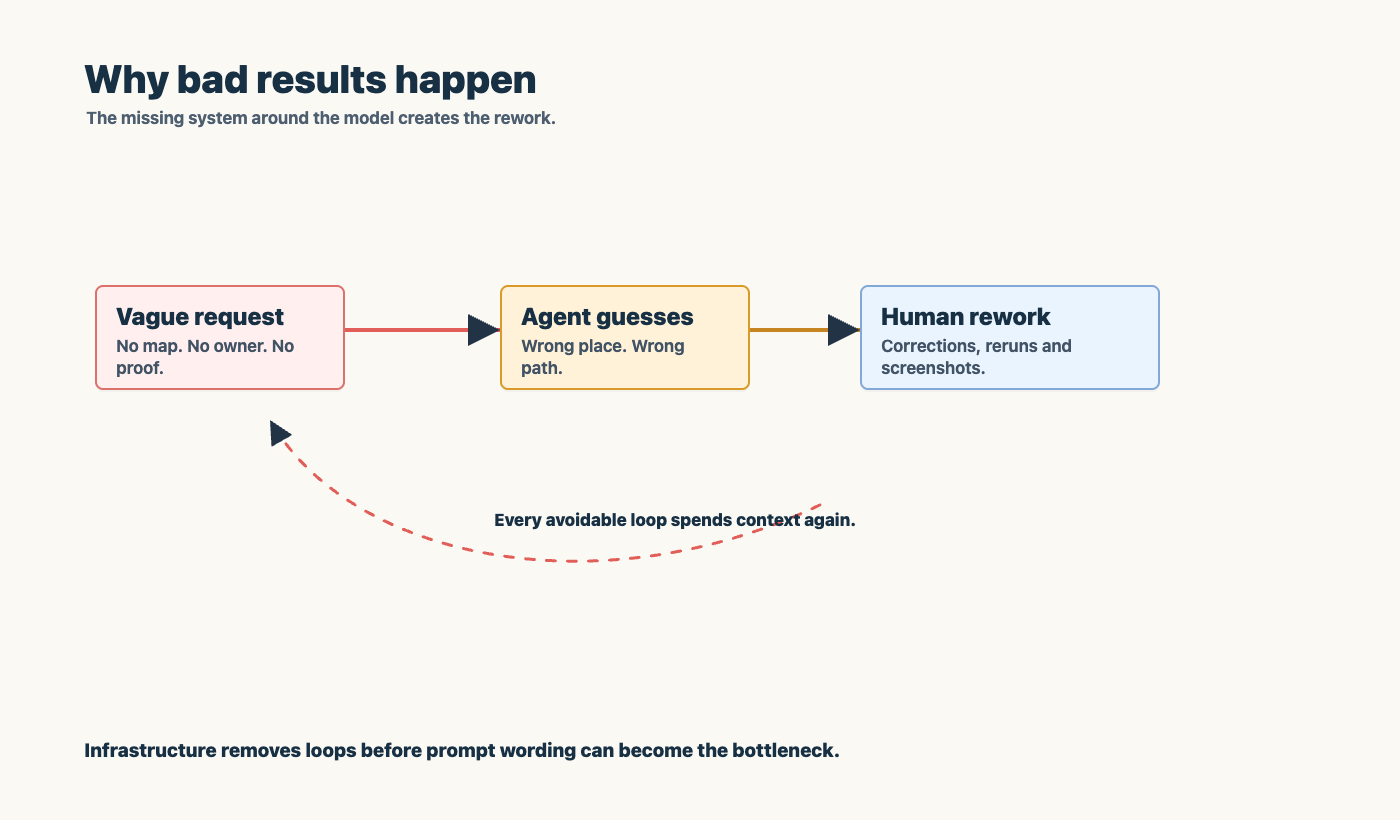
Most bad agentic results are not mysterious. They happen when someone asks an agent to behave like a professional team, but gives it none of the machinery a professional team depends on.
The task exists only in chat. There is no owner, status, history, acceptance criteria, or audit trail.
The source of truth is unclear. The agent sees a live host, a local checkout, a branch, a stale note, and a few half-remembered commands, then has to guess which one matters.
The context is too broad or too vague. More text is added, but the system still does not know which runbook applies.
The proof step is optional. The agent produces plausible code or prose, but nobody has forced it to run the relevant tests, open the browser, inspect logs, or verify the deploy.
This is not a model intelligence problem first. It is an operating model problem.
The useful question is not “how do I prompt the agent better”. The useful question is “what infrastructure routes a work request into the right evidence path”.
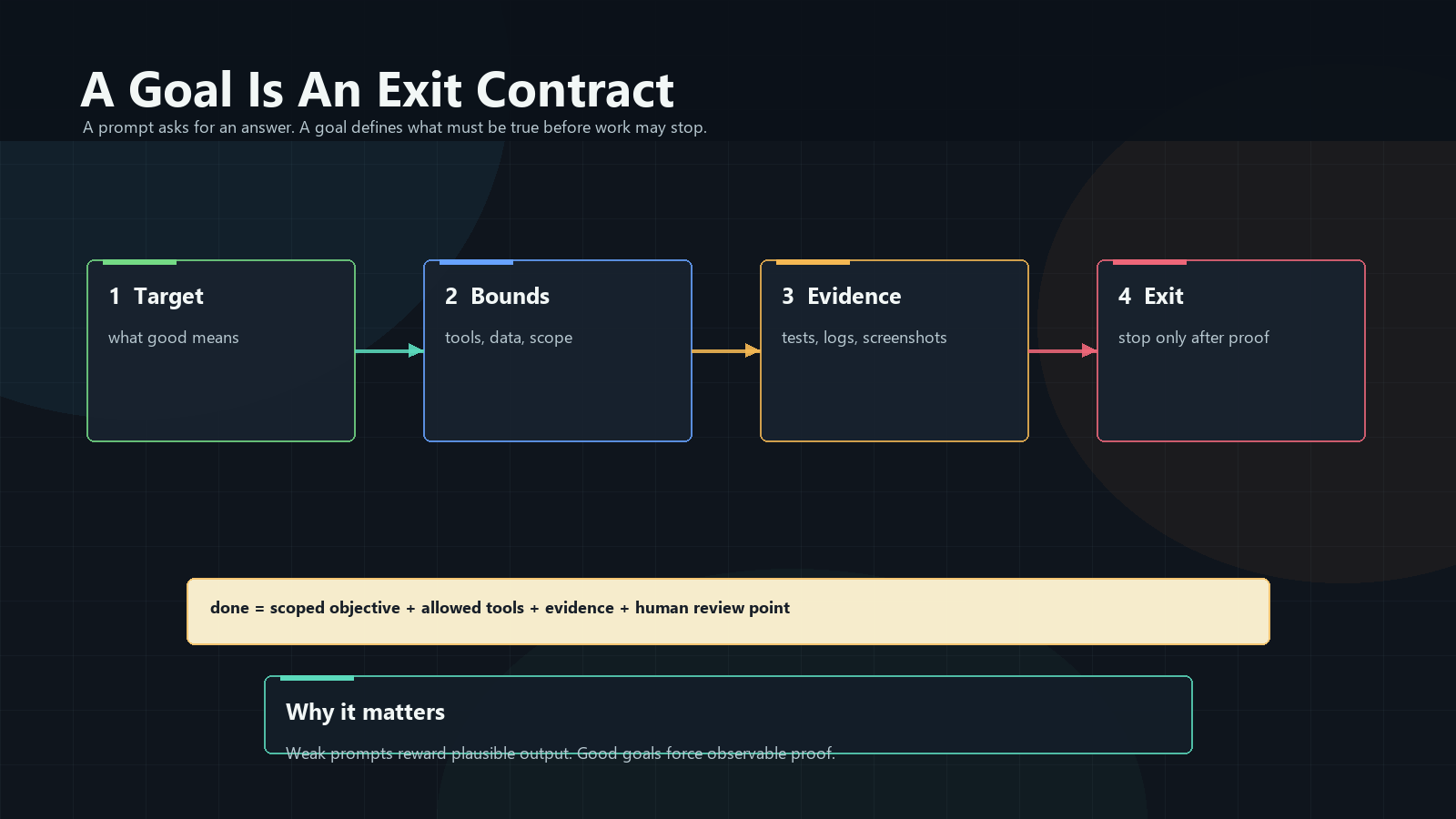
What the contract must decide
An agent.md worth caring about answers boring questions very explicitly.
Where am I working?
Which repository is the deployable source of truth?
Which host is development, which host is production, and which host is only a runner?
Which tools are legitimate for this task?
Which files are operating rules and which files are implementation details?
What must be documented when a lesson is learned?
What proof is required before the work can be called done?
What is never acceptable, even if it would make the current task look finished?
That last question is where quality starts.
In my own setup, agent.md says that origin/main is the deployable truth, web changes require browser evidence, host-to-host copying is not a normal deploy path, fallback-by-default is not a production architecture, and certain kinds of work have dedicated runbooks. It also points the agent to the backlog, pipeline tools, DNS tooling, backup scripts, browser-capture flow, and domain-specific docs.
The point is not to make a long instruction file for its own sake. The point is to make the path of work obvious enough that the agent does not invent a new process every time.
Access is not magic
People often imagine two extremes: either the agent is only a chatbot that suggests commands, or it is an all-seeing thing with unlimited access.
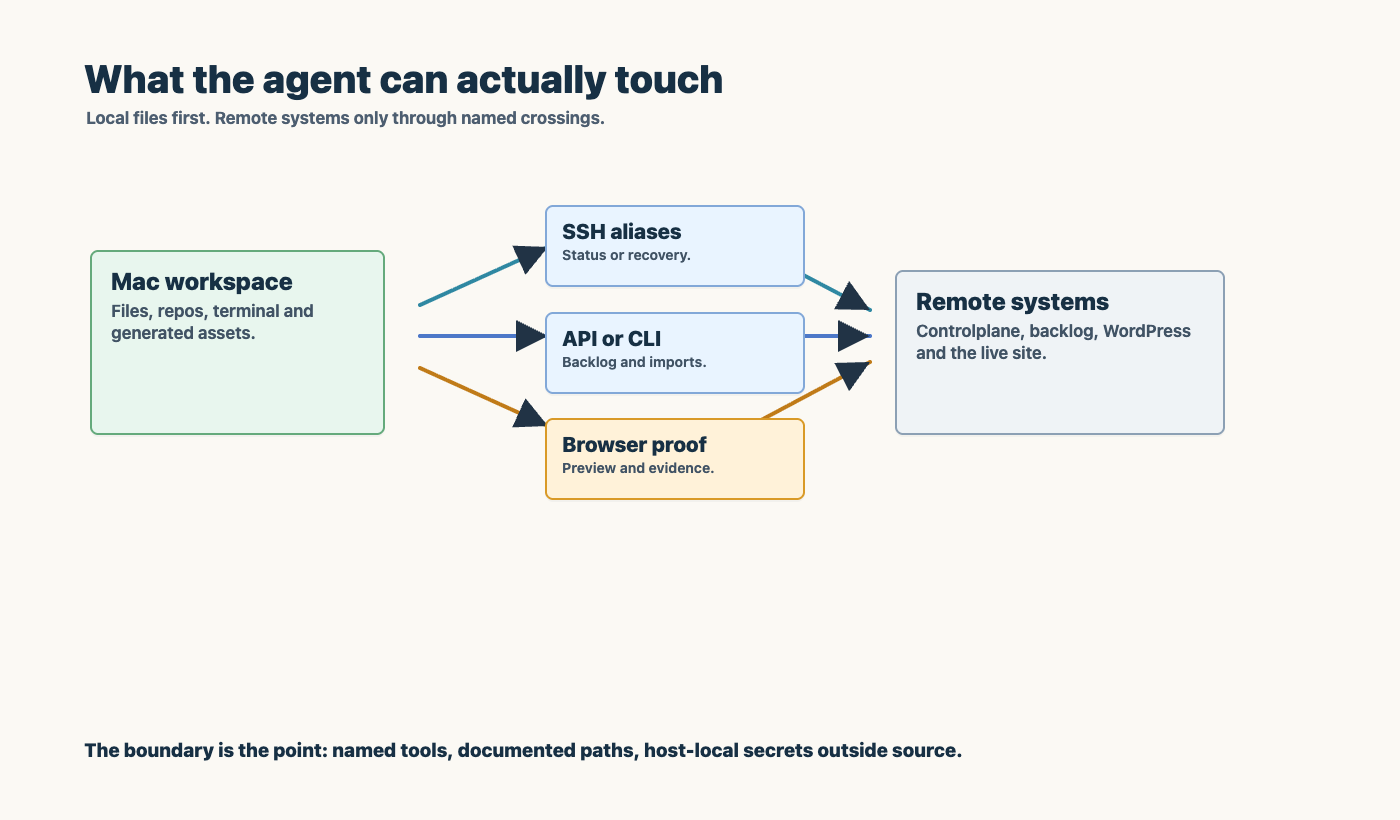
The useful middle is more concrete.
The agent works in a workspace. It can inspect a managing Git repository with rules, runbooks, scripts, desired-state files, and lesson documents. It may run commands on the local machine. Sometimes it may connect to another system over SSH. More often, it interacts through a pipeline, an API, or a browser validation script.
That means the important design question is boundary design.
An agent does not need every credential. It needs the right role for the task. If it can deploy through a pipeline, the pipeline should carry the production access. If it can inspect browser state through a capture script, it does not need to improvise a manual test flow. If it can update DNS desired state through a repo tool, it should not log into a provider console as a human.
Good agentic work feels powerful because it is bounded, not because it is unlimited.
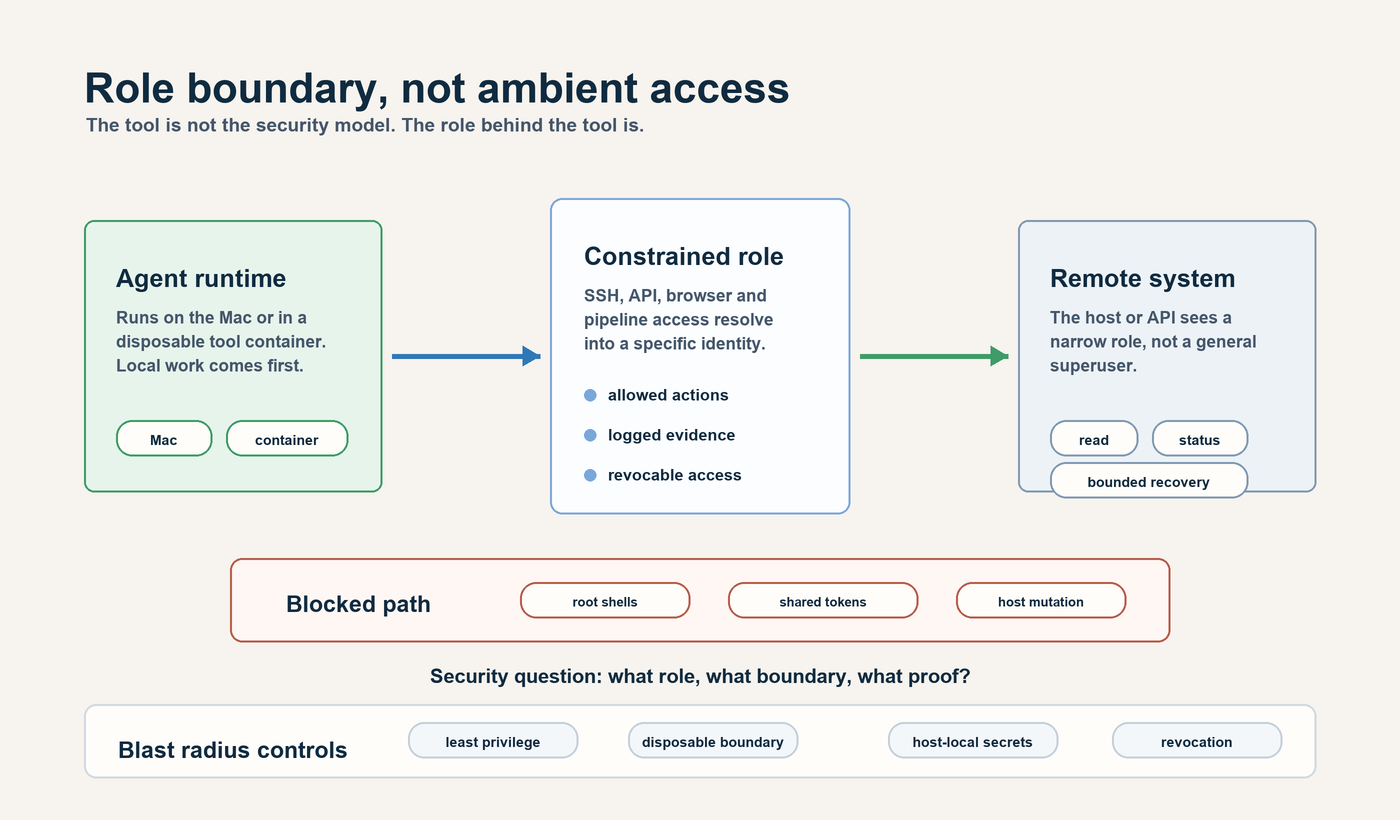
Security is role design
Agentic work does not create a new physics of security risk. A shell is still a shell. An SSH key is still an SSH key. An API token is still an API token.
What changes is frequency and speed.
More work is attempted. More paths are explored. More commands are run. An agent is also good at finding a route when the first route fails. That is useful in engineering and dangerous in weakly governed systems.
So the question is not “does the agent have SSH”. The question is what role that SSH identity has.
An SSH key into a restricted user inside a disposable container is very different from a key into a privileged long-lived host. A token that can open a pull request is different from a token that can mutate production state. A browser testing account is different from a tenant admin account.
The same role discipline we already know from infrastructure applies here:
least privilege
short-lived credentials
scoped service accounts
disposable execution contexts
audited command paths
separation between development, deployment, and production control
no hidden fallback path that bypasses the real release process
This is why agent.md should say what kind of access is legitimate, not only what command to run.
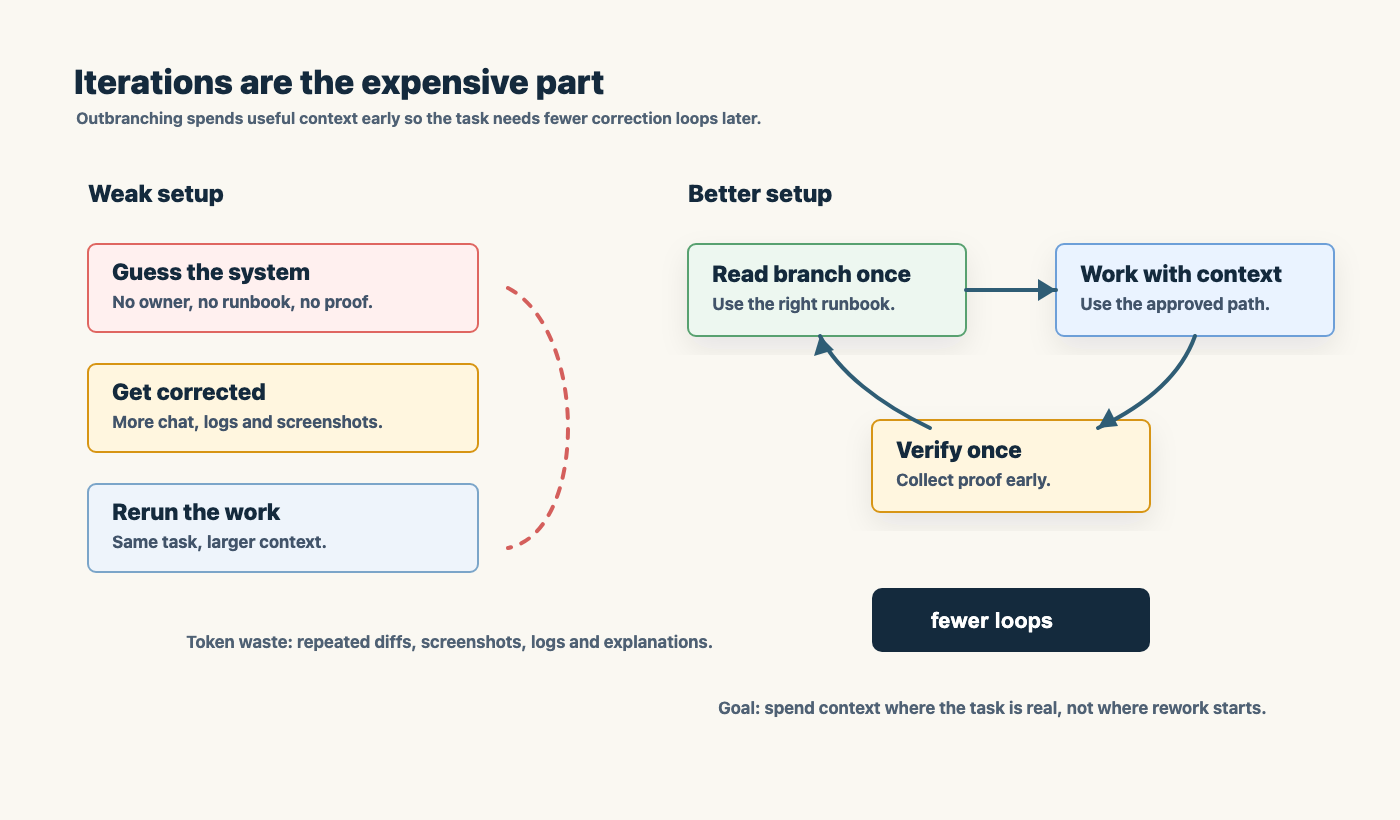
The real token eater is iteration
People worry that a serious agentic workflow must use too many tokens because it reads runbooks, checks files, opens browsers, captures screenshots, and writes evidence.
That is the wrong comparison.
The expensive path is not “the agent read the right context”. The expensive path is “the agent guessed, did the wrong thing, got corrected, guessed again, broke layout, got corrected again, then finally discovered the rule it should have read first”.
Iteration is the real token eater.
Visual verification is expensive, especially screenshots. But it is also where many frontend lies die. A page can have green tests and still have overlapping text. A code block can exist and still be unreadable on mobile. A browser preview can reveal broken images that a Markdown check will never see.
The job is not to minimize every single token. The job is to reduce wasteful correction loops.
Outbranching from agent.md helps. The root file should not contain every command in the universe. It should route the agent to the specific runbook for the task: browser testing, pipeline release, DNS work, PCB design, Broadcom documentation, backup flow, or whatever domain is actually relevant.
Good context is cheaper than repeated confusion.
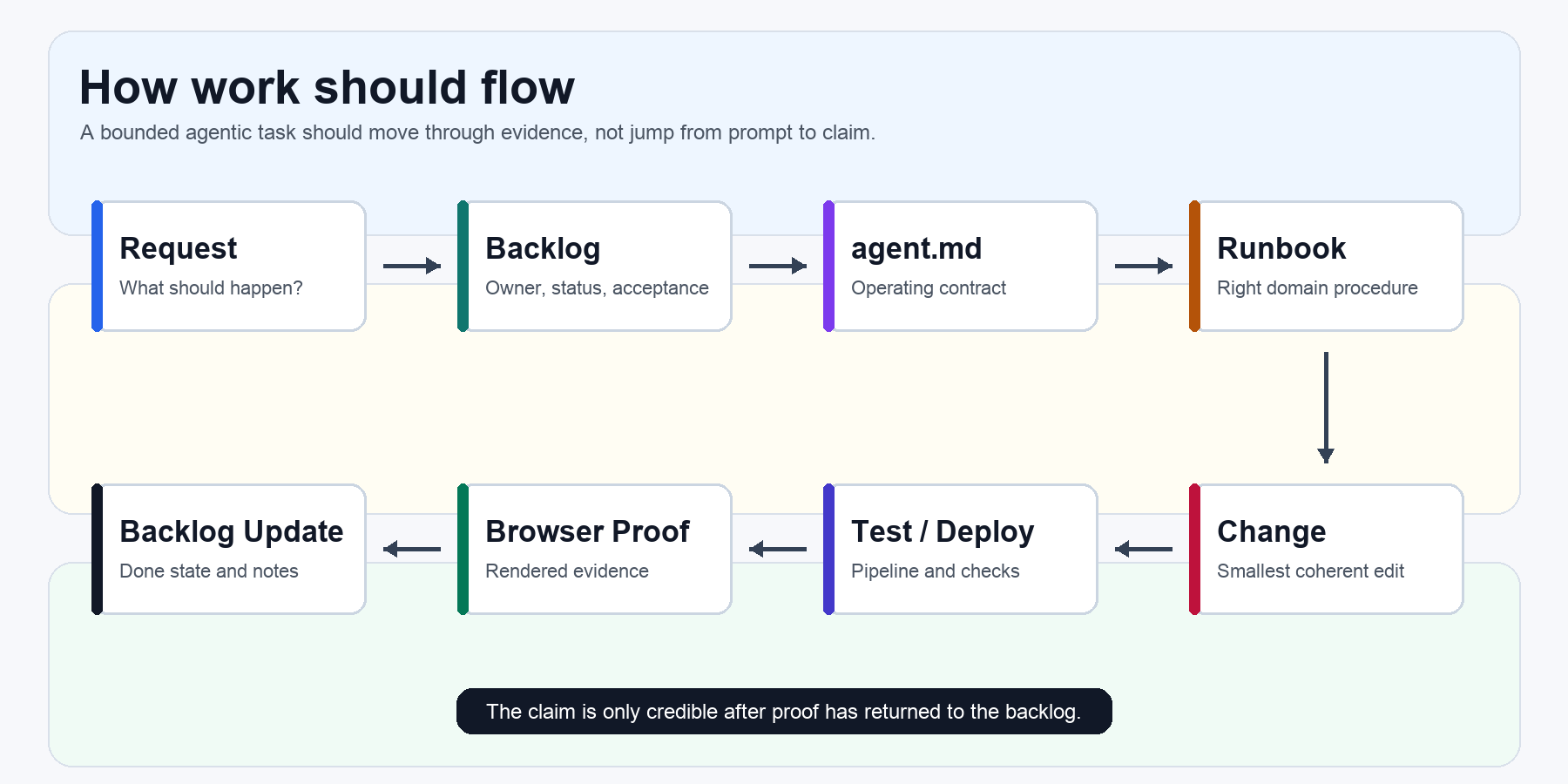
How work should flow
When I ask for work, I do not want the agent to jump straight from request to finished claim.
I want a path:
the task goes into the backlog, so it has an owner, status, priority, and a place to store progress
the agent orients itself by reading the root operating contract, checking the repo state, and finding the relevant runbook
the change stays as small as reasonably possible and follows the existing codebase
verification produces evidence: screenshots, DOM output, console logs, page errors, failed requests, API responses, targeted tests, deploy status, or rendered-page review
the backlog gets updated and the repo is left clean
That may sound formal, but it is less work than recovering from invisible drift.
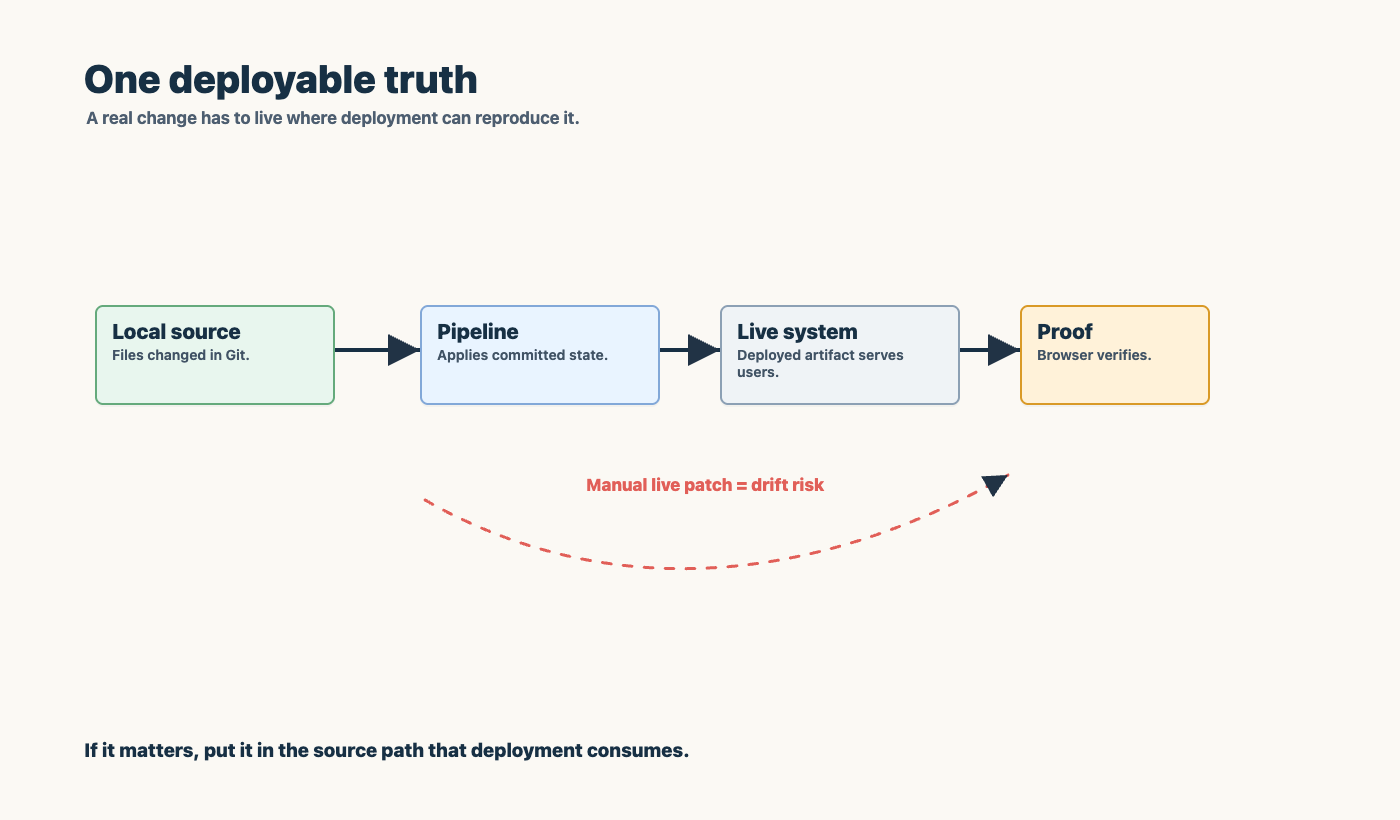
One deployable truth
Agentic work gets messy fast when there are multiple truths.
There is the local file. The branch. The deployed host. The admin panel. The pipeline artifact. The browser preview. The note in chat.
If those drift apart, the agent becomes a high-speed confusion amplifier.
That is why I care so much about one deployable truth. The normal path should be:
change source
commit intentionally
push
let the pipeline deploy
verify the deployed artifact
record the proof
Host-local fixes are sometimes necessary in emergencies, but they should not become the operating model. If a fix matters, it goes back to source. If a lesson matters, it becomes a test, a runbook, or an operating rule.
Chat is a terrible system of record. Git, backlog, tests, and runbooks are better.
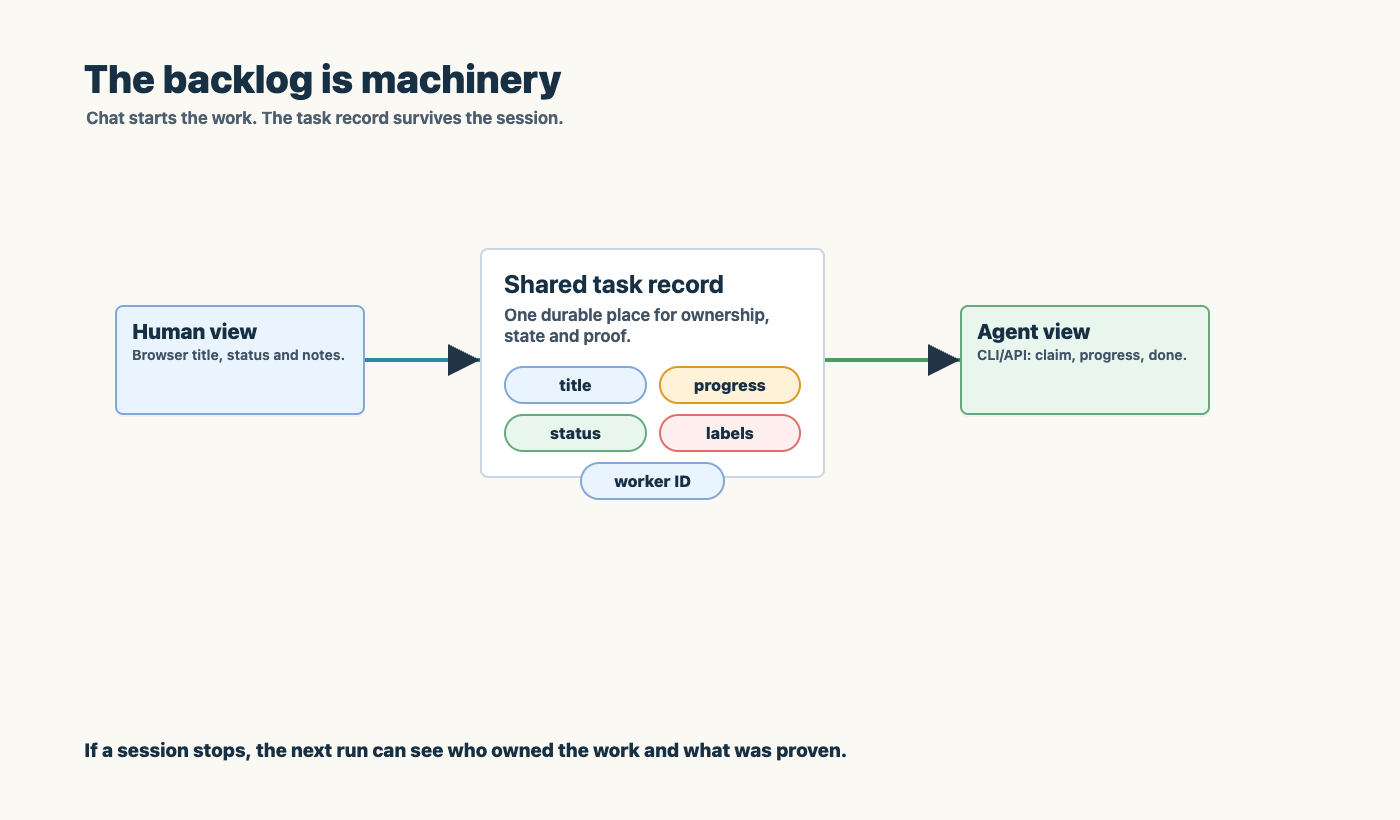
The backlog is machinery
The backlog is not administrative decoration. It is part of the machine.
For a human, the backlog is a browser view. I can read tasks, review priority, and decide what matters next.
For the agent, the backlog is also an API or CLI. It can claim work, update progress, release a lock, or mark a task done.
That shared interface solves a practical problem: the work no longer lives only in a conversation. If a run stops halfway through, the next run can see the task, status, worker, and progress note. If I ask for a release, there is a record that the release happened. If the agent is blocked, it can say where and why.
That sounds mundane until you run more than one agentic task in a day. Then it becomes the difference between a system and a mess.
Agent Drift
There is a second kind of drift that deserves its own name: Agent Drift.
Configuration drift happens when systems slowly disagree with the desired state. Agent Drift happens when different agent runs learn different lessons and write them into different places.
One run discovers that browser validation needs a special login path. Another run discovers that DNS changes must go through a desired-state file. A third run learns that a host-local workaround is dangerous. If those lessons remain in chat, or get written into random notes, the next agent may not inherit them.
Now the agents are not only changing code. They are changing the operating model in contradictory ways.
The fix is boring and important:
durable lessons go into the right runbook
recurring bugs become tests
new access paths are documented where future work will look
old guidance is superseded, not silently deleted
root rules route to deeper docs instead of duplicating everything
An agentic engineering environment should learn, but it should learn through controlled memory. Otherwise you do not get organizational learning. You get sediment.
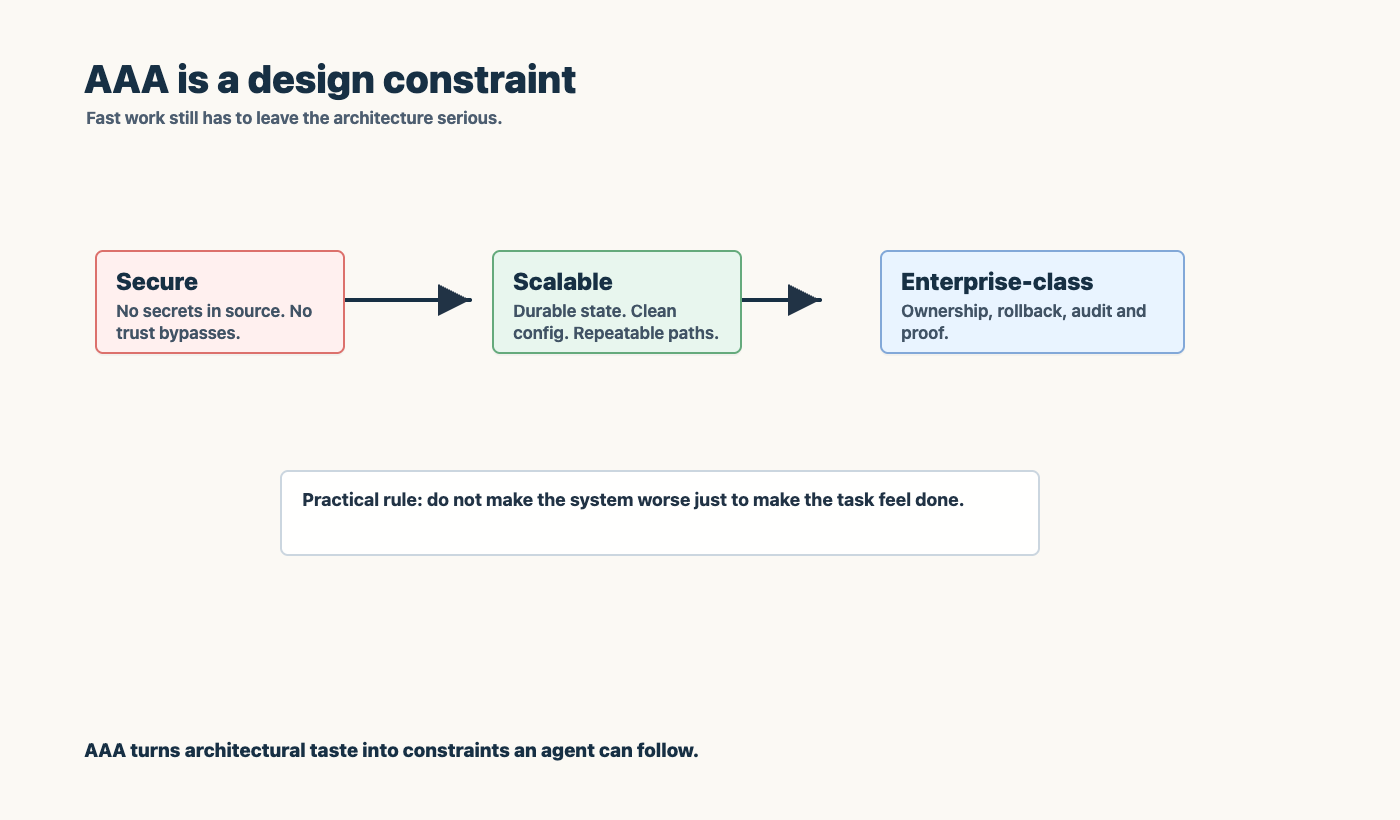
AAA is a design constraint
One of my strongest rules is that the agent should take the AAA path: secure, scalable, enterprise-class architecture with no shortcuts.
That does not mean every lab has to be production. It means the architecture should not become worse just because the agent wants the task to look done.
The agent should not normalize insecure transport. It should not add certificate bypasses as a steady state. It should not invent fallback logic that hides broken infrastructure. It should not patch a live host and leave source behind.
This is a style of programming as much as a security rule.
It pushes the agent toward explicit contracts, environment-based configuration, stateless processes where possible, real backing services, reproducible startup, and tests that capture the bug that was fixed.
The current task is never the whole system. The agent has to leave the system more coherent than it found it.
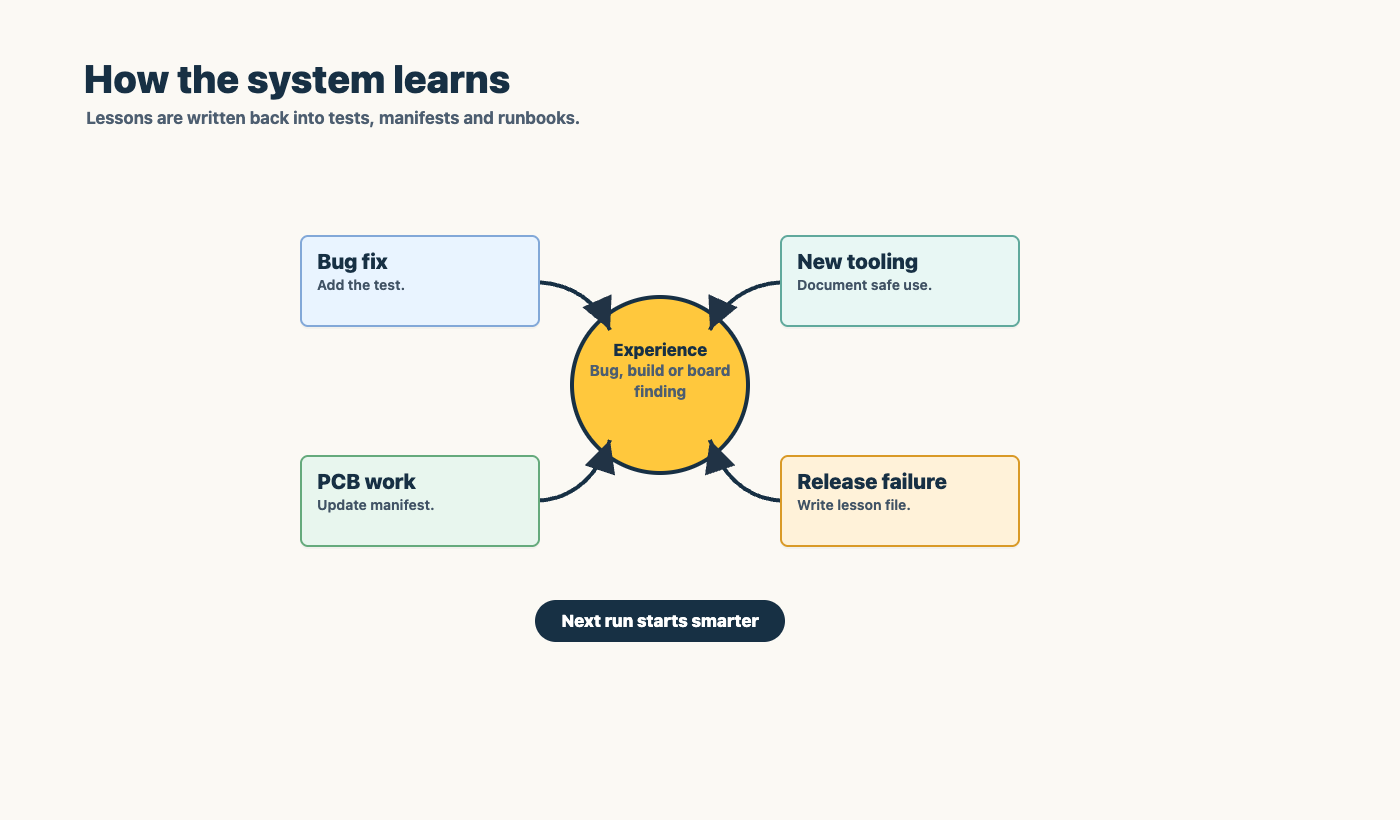
Learning without mythology
When people say “the agent should learn”, they often mean something vague. I want something more operational.
A system learns when the next run has better structure than the previous run.
That can happen through:
a new regression test
a clearer runbook step
a stricter validation script
a documented access path
a backlog note that preserves handoff state
a rule that prevents a repeated failure mode
The learning should live where the next agent will actually read it. A PCB lesson belongs in a PCB manifest. A browser testing lesson belongs in the browser testing runbook. A pipeline lesson belongs in the release workflow. A security access lesson belongs in the tooling and access journal.
This is how agentic quality compounds. Not through vibes. Through memory attached to the system.
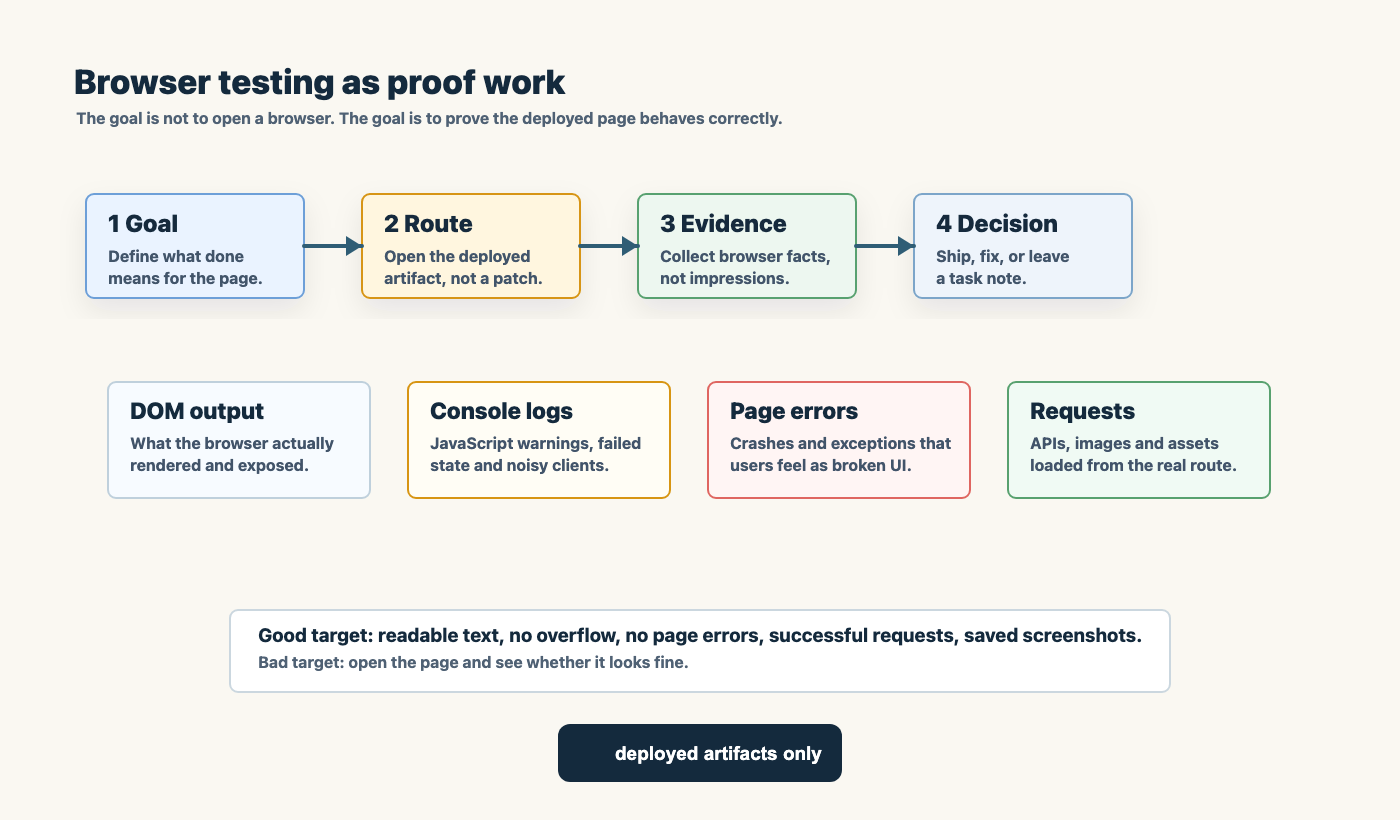
Browser proof is proof work
For web work, I do not trust a final answer that says “it should look right”.
The browser has to be part of the proof.
That means inspecting the rendered page, not only the source. It means checking screenshots, DOM output, console logs, page errors, failed requests, API responses, and performance data. It means mobile as well as desktop when layout is involved.
This matters because frontend bugs are often visual and contextual. Text can overlap only at one width. A copy button can float in the wrong place only while scrolling. An image can be present in Markdown but broken in WordPress. A code block can be syntactically correct and still unusable on a phone.
Agents are very good at producing plausible claims. Browser proof turns plausibility into evidence.
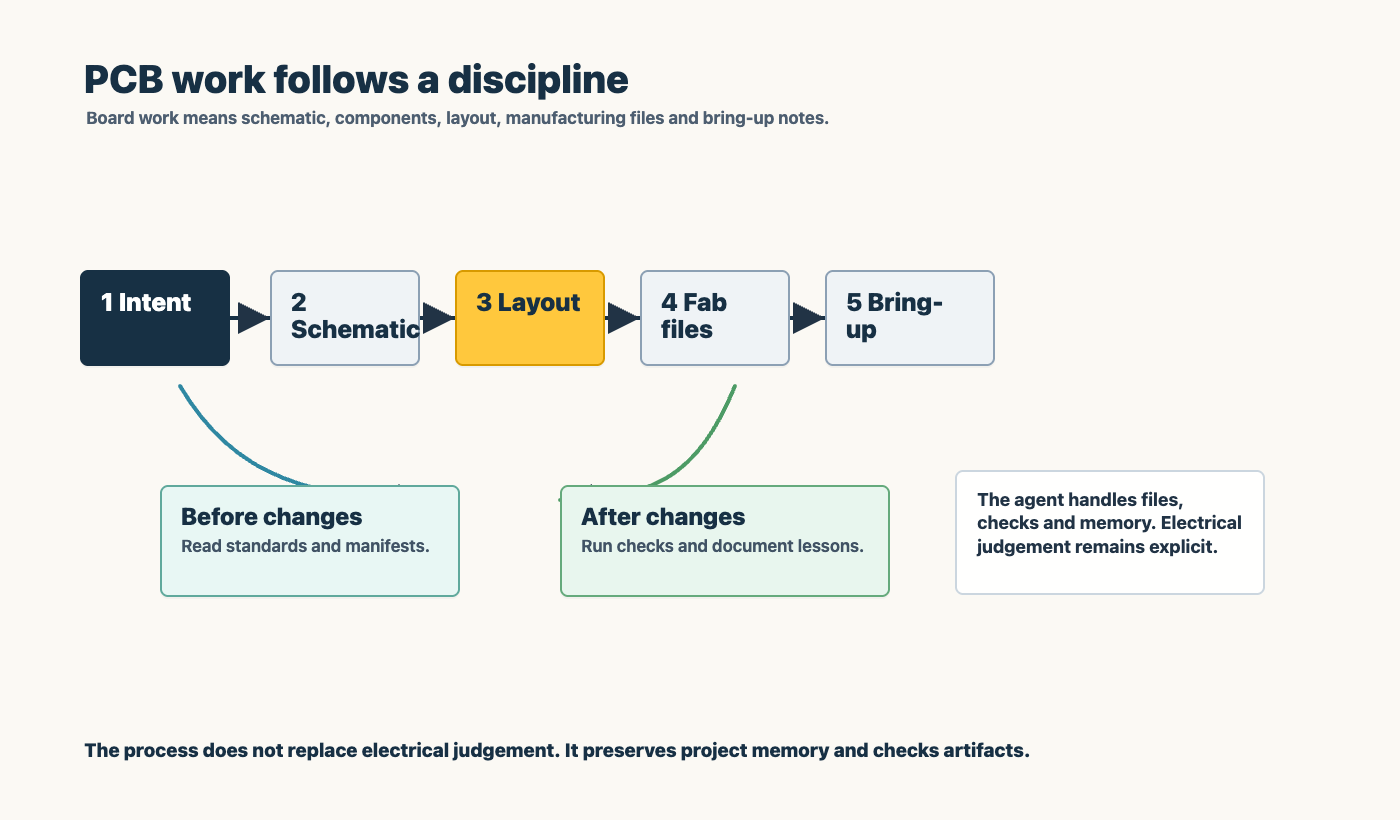
A short hardware example
PCB development is useful as a small example because it shows that this is not only a software pattern.
If an agent works on a board, it should not just open KiCad and start moving traces. It needs the board manifest, design rules, cost constraints, lessons from prior revisions, fabrication assumptions, and verification expectations. If it discovers a routing pattern that prevents a repeated failure, that lesson should go into the durable PCB manifest.
That is the same pattern again.
The operating contract routes the work into the right domain memory. The result is not only one better board. It is a better next run.
What others can copy
The exact files in my setup are personal. The pattern is portable.
If you want better agentic work, start with a small operating contract:
name the source of truth
define the normal deploy path
make task tracking mandatory
document which tools are legitimate
separate local work, runners, and production systems
require proof for browser-visible changes
put domain lessons where future runs will find them
mark lab shortcuts as lab shortcuts
forbid shortcuts that make production architecture worse
Then branch out from the root file. Do not make one giant instruction document. Use it as a router.
The thesis is simple: agentic engineering is infrastructure, operations, and knowledge management before it is prompting.
Partially AI-modified / AI transparency: This publication is AI-assisted and human-reviewed. Constantin Korte assumes editorial responsibility. See AI Transparency.
TL;DR
Agentic on-prem AI is now cheap enough to matter for persistent attacks. Open weights lower the barrier, tools create the loop, and removed safety brakes turn strong models into practical attack engines.
Douglas Adams gave the Guide the right warning label: “Time is an illusion.
Lunchtime doubly so.”
In security, cheap retries are the uncomfortable punchline: a machine can keep
trying long after a human would have stopped.
Early LLM safety relied on friction: model refusals, API blocks, rate limits,
logging, reviews, account trust, and a chat window that mostly returned text. A
human still had to turn the answer into commands, context, and follow-through.
Practically, the shift is simple: agents connect models to tools, files,
browsers, terminals, repositories, and credentials. Open-weight models such as
GLM-5.2 are reaching frontier-class tool benchmarks. Heretic is a public project
for removing or weakening refusal behavior in transformer models. The short
version: the “no” can be removed after a model is published. If the model no
longer refuses the task, the real question is how far the agent can get before
a person stops the run.
Security often changes when repetition gets cheap. Reconnaissance,
categorization, validation, and pentest-style follow-through now take less
manual effort to repeat. Attackers do not all become experts overnight. More
people can run more attempts, against more targets, with fewer manual steps.
Some attempts will reach systems that were skipped because manual follow-through
was too expensive.
Three public signals point in the same direction. Anthropic’s Mythos Preview
shows specialized cyber capability jumping above Opus 4.6 on cyber benchmarks.
Z.AI reports GLM-5.2 close to Opus 4.8 on selected terminal and tool benchmarks,
and ahead of GPT-5.5 on at least one long-horizon benchmark in its own report.
Heretic showed about 25,000 GitHub stars when I checked it on June 21, 2026.
Together, they suggest stronger loops, cheaper runs, and refusal barriers that
are easier to remove.
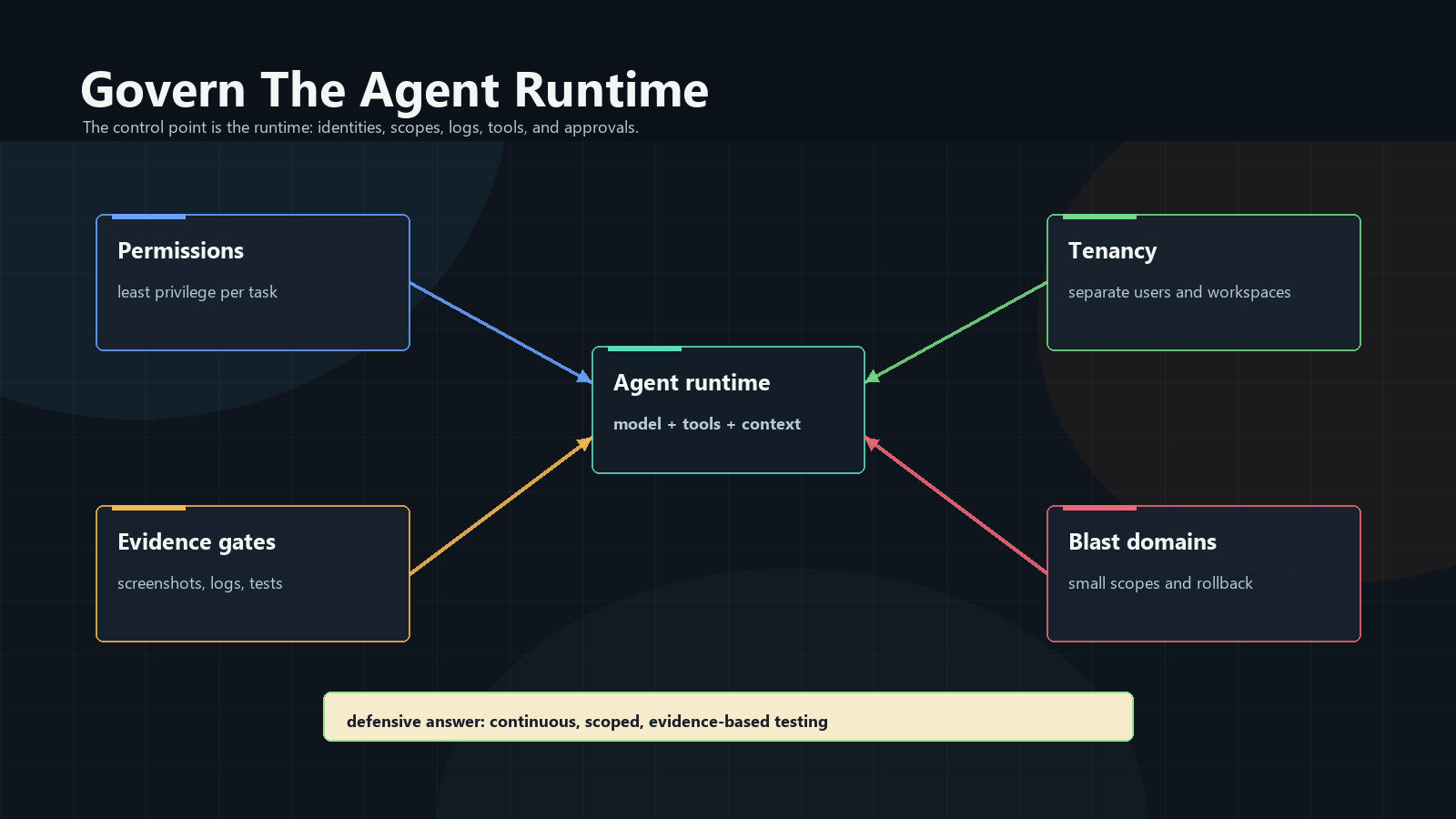
The practical control point is the whole run: where it executes, which identity
it uses, which data it can read, which tools it can call, and what evidence
proves it should stop.
From Chat To Work Loop
By “chat” I mean a normal LLM chat such as ChatGPT or Claude in a browser. The
model returns text, then waits. The person copies commands, checks output,
chooses the next step, retries, and remembers what failed.
An agent moves part of that work into software. It can keep a goal, call tools,
read files, run commands, open a browser, inspect output, and continue. A failed
step becomes the next input, not the end of the conversation.
Four terms matter:
A chat response is content.
A tool call is action.
An agent run is a work loop with permissions.
A goal adds a stop condition.
The product name matters less than the software around the model. Codex,
OpenHands, Claude Code, and similar tools give the model a workspace: files, a
shell, a browser, a repository, logs, and approval buttons. The model writes
text. The workspace decides whether that text can read a secret, run a command,
or change a system.
Plain terms help because the risk starts when text gains a path to action.
Term
Plain meaning
What changes in the run
Runtime or harness
The controlled workspace around the model.
It decides permissions, logs, tools, approvals, and stop rules.
Tool call
The agent requests an action from the runtime: read a file, run a command, open a browser, call an API.
Text becomes action at this point.
MCP
A standard way to connect an agent to external tool servers.
It can expose approved tools to the run, but it also expands what the run can touch.
AGENTS.md or instruction file
A project note that tells the agent how to work in a specific repo or environment.
It can add local rules and knowledge the base model did not know before the run.
Retrieval or vector database
A search layer that feeds relevant documents or prior knowledge into the agent.
It can add knowledge the base model did not already carry, so source quality and access control become part of the risk.
Context window
The working memory the model can process at once, measured in tokens.
Long runs may compress, retrieve, or forget details; evidence should not depend on memory alone.
Blast radius
The maximum damage or data exposure one run can cause.
Smaller blast radius means one bad run is easier to contain.
Where The Agent Runs Matters
The same model can be low risk in one place and dangerous in another. A cloud
run may stay inside a vendor sandbox. A local run may touch a developer laptop,
WSL, a lab network, or an internal admin machine. A managed runtime sits between
those cases, with scoped credentials, network rules, logs, and review gates.
Location sets the blast radius: which identities, files, secrets, networks, and
business systems the run can reach. Once text can become action, the next
question is where that action lands.
The operating check is simple:
Which agent runs where?
Which identity does it use?
Which data and tools can it touch?
Which logs, approvals, and stop rules govern the run?
Prompt Versus Goal
“Write Pong in Go” is a prompt.
“Write Pong in Go, create a test suite, measure memory and performance, prove it
can run smoothly, collect screenshots, and reconcile any failure before
stopping” is a goal.
The second version changes the job. It gives the agent a finish line, a way to
judge progress, and a reason to keep going after the first imperfect answer.
A goal turns output into follow-through. The agent can try, inspect, fix,
measure, and continue until the proof is good enough or a limit is reached. The
same pattern applies outside software: HR, finance, operations, and security all
need goals with limits and proof, not just clever text.
A goal should name:
the target outcome
the allowed tools
the forbidden actions
the data and systems in scope
the evidence required before “done”
the budget or time limit
the human review point
That structure matters for security. A weaker model inside a strong loop can
beat a stronger model used once and abandoned. Persistence turns rough answers
into work, and work is what defenders must control.
The Safety Barriers Are Easier To Remove
Safety barriers are the friction that made early LLM misuse awkward: model
refusals, system prompts, API policy checks, monitoring, rate limits, account
trust, product UX, and a normal chat product that mostly returned text.
Early LLMs were safer partly because misuse was clumsy. A model could suggest a
direction, but a human still had to turn the answer into commands, install
tools, debug errors, keep context, and decide the next step. Most use was
tinkering, not continuous operation.
Agents remove much of that friction. The same model can now sit inside a loop
with a browser, shell, repository, file system, MCP tools, credentials, logs,
and a goal. It can try something, read the result, adjust, and try again. The
important change is cheaper follow-through.
Heretic targets another layer: refusal behavior. It does not give the model
secret cyber knowledge by itself. Knowledge can still come from retrieval,
AGENTS.md files, tool output, MCP servers, documentation, or a vector database.
Heretic matters because it makes one visible safety brake easier to remove while
open-weight models are becoming strong enough for serious tool work.
The main story is the combination: loops, Heretic-style refusal removal, and
frontier-class open models. A malicious agent no longer needs to live behind a
major hosted provider. It can run locally or in someone else’s cloud account,
with private tools and private knowledge attached. Many runs will still fail.
The entry barrier is lower anyway.
Recent evidence supports that concern. OpenAI describes GPT-5.5 running
multi-day vulnerability-research campaigns in VulnLMP. Anthropic reported
Mythos Preview beating Opus 4.6 on CyberGym and Terminal-Bench. Z.AI reports
GLM-5.2 close to Opus 4.8 on selected terminal and MCP benchmarks. The tests
differ, but the operational concern is plain: capable models can already do
serious multi-step tool work. Put that capability inside a loosely governed
agent harness, and chat-era refusals are no longer enough.
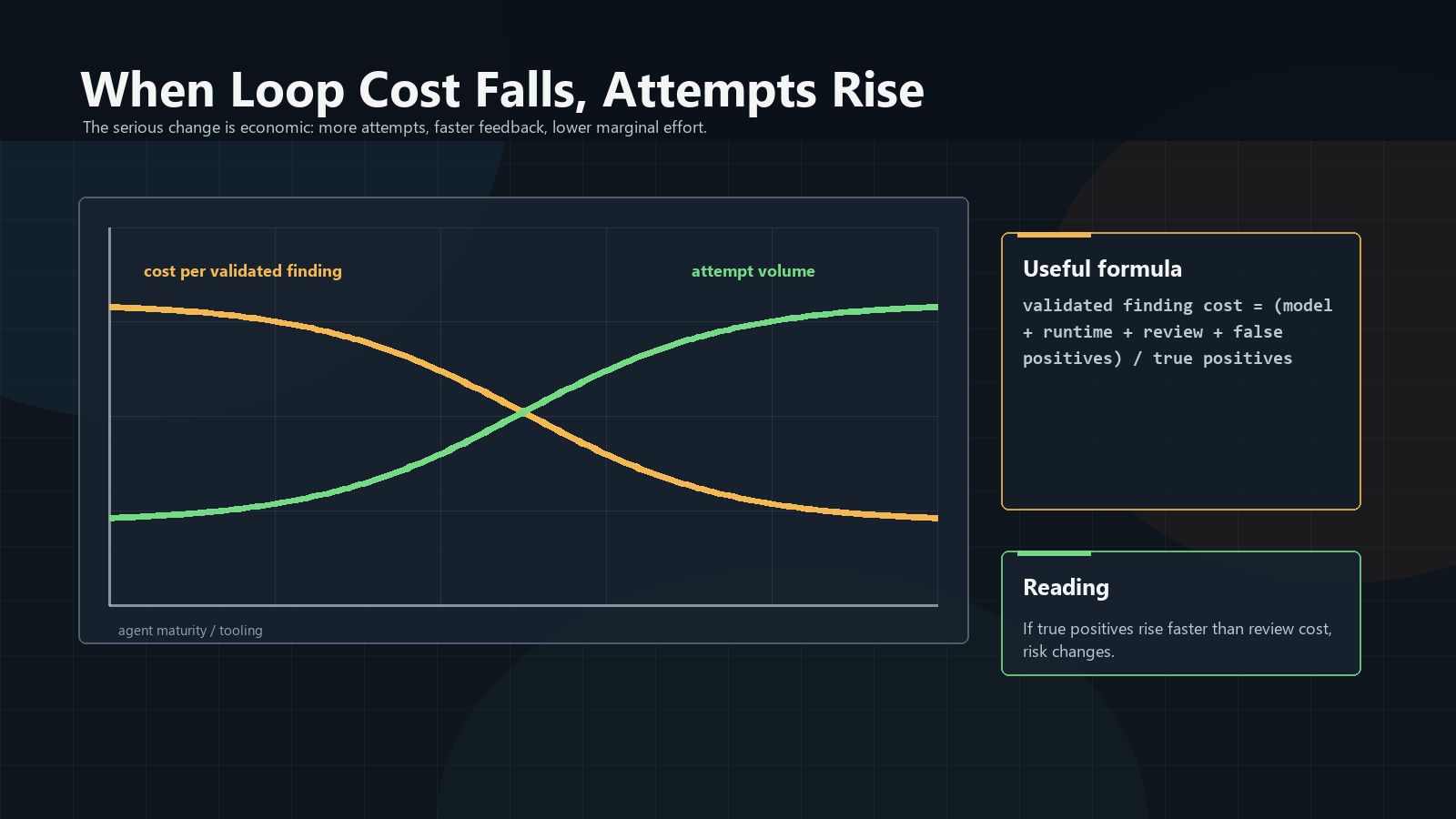
The Economics Are The Warning
Track the cost per validated finding. Count model cost, runtime, sandboxing,
tools, human review, and false positives. Divide that by the number of true
positives.
Cheaper follow-through means more attempts. If true positives rise faster than
review cost, staffing and review budgets change.
Bad agents still waste money. Good harnesses still produce false positives.
Local models may be weaker than hosted frontier models. Hosted models may have
better monitoring and abuse controls than a random local setup. No setup wins
across every workload.
Plan for more actors running more attempts against more targets for less
marginal effort. Some attempts will be noisy. Some will be wrong. Some will find
the thing nobody has looked at in two years.
Persistence Changes The Distribution
The main risk is not smarter attackers. The main risk is cheaper repetition.
Many cyber tasks are normal IT work repeated many times: read code, read logs,
check dependencies, read command output, sort findings, and decide the next
step. A general model already has many of those skills: programming, Linux,
networking, debugging, and language.
Extra security knowledge can be added later through documentation, search,
retrieved notes, AGENTS.md files, MCP tool servers, scan output, and results
from earlier runs. MCP just means a standard way to connect an agent to tools.
The chart says one simple thing: when one attempt gets cheaper, more attempts
happen. More attempts means more old VPNs, forgotten admin panels, stale
dependencies, exposed backups, and internal tools get checked.
The public evidence is already strong enough to plan for. Anthropic’s Project
Glasswing shows what a special cyber model can do: Mythos Preview scored 83.1%
on CyberGym versus 66.6% for Opus 4.6. Glasswing partners also reported more
than 10,000 high- or critical-severity findings.
OpenAI’s GPT-5.5 VulnLMP result shows the same pattern with a top hosted model
and tools. It ran multi-day vulnerability research, reproduced crashes, and
wrote root-cause analysis. It did not prove a fully automatic critical exploit
chain in that test. It still shows that long tool runs already matter.
Availability changed after that. Anthropic says a June 12, 2026 US
export-control directive forced it to disable Fable 5 and Mythos 5 for all
customers. So the Glasswing numbers are evidence from a limited preview window,
not a product someone can simply buy today.
The cyber-model lesson is simple: the bottleneck moves. First, the model finds
more issues. Then the hard work becomes checking which findings are real,
setting priority, disclosing responsibly, and patching fast enough.
Public signal
Reported detail
Source
Claude Mythos Preview
83.1% on CyberGym vulnerability reproduction, versus 66.6% for Opus 4.6.
Open-weight models change who can run this kind of work. “Open-weight” means
the model can be downloaded and run outside the vendor’s hosted service.
GLM-5.2 has a 1M-token context. In plain English: it can keep a lot of
instructions, logs, code, and notes in one run. On Z.AI’s own table it is close
to Claude Opus 4.8 on tool tests: 81.0 versus 85.0 on Terminal-Bench 2.1, and
76.8 versus 77.8 on MCP-Atlas. Z.AI also reports GLM-5.2 slightly ahead of
GPT-5.5 on one long-task benchmark.
The connection is direct. Mythos shows how strong agentic models can create a
flood of security findings. GLM-5.2 shows that open models are getting close to
top hosted models on tool work. Heretic-style refusal removal can remove or
weaken one safety brake. Put together, this creates a private model that can run
with tools and keep trying.
The cost is low enough to matter. A useful attack loop needs a model, a goal,
tools, memory, retries, and a way to check results. It does not need a special
cyber model for every step. If the loop is cheap enough, smaller malicious
groups can run many more attempts.
A high-level setup looks like this:
one 8x B200/HGX-class GPU server
2-4TB system memory
fast local storage
software that runs a compressed open model such as GLM-5.2
agent software that connects the model to tools, search, logs, and review
For defense, every part of that setup needs strict permissions and logging. For
misuse, the same setup can run with weaker safety and keep retrying.
The hardware is not small. GLM-5.2 is very large. In full precision, its weights
alone are about 1.5TB. In practice, operators compress the model and batch many
requests together. Unsloth puts 8-bit inference around 810GB of total RAM plus
GPU memory. An 8x B200 node has about 1.44TB of fast GPU memory, so it is in the
right hardware class. Public 8x HGX B200 listings are already in the low-$400k
range before support, networking, and rack work. A rough $400k-$600k server,
paid over three years and kept busy, lands around $20-$25 per hour after power
and cooling.
Busy-node output throughput
Approx. node cost at $21/hour
2,500 tokens/s
$2.33 per 1M generated tokens
5,000 tokens/s
$1.17 per 1M generated tokens
Break-even vs Z.AI GLM-5.2 output API
about 1,326 tokens/s
Break-even vs GPT-5.5 output API
about 195 tokens/s
Break-even vs Mythos Preview output API
about 47 tokens/s
These are not guaranteed speed numbers. Long context, compression, batching,
latency, and serving software all change the result. The important part is the
break-even line. Once a busy node produces about 1,326 generated tokens per
second, it is already cheaper than Z.AI’s public GLM-5.2 API output price. It
beats GPT-5.5 output pricing at roughly 195 tokens per second and Mythos Preview
pricing at roughly 47 tokens per second.
Reference price
Public price point
Claude Mythos Preview
$25 per 1M input tokens, $125 per 1M output tokens after preview credits
OpenAI GPT-5.5
$5 per 1M input tokens, $30 per 1M output tokens
OpenAI GPT-5.4
$2.50 per 1M input tokens, $15 per 1M output tokens
Z.AI GLM-5.2 API
$1.4 per 1M input tokens, $4.4 per 1M output tokens
8x B200 GLM-5.2 on-prem scenario
about $1-$2.50 per 1M generated tokens at 2,500-5,000 tokens/s, before staff and datacenter overhead
A malicious group does not need Mythos access to run persistent attacks. It can
use open models with strong general tool skills, remove or weaken refusals, add
its own notes and tools, and spend GPU time instead of buying a hosted model
with the provider’s safety checks. The cost changed, and the safety
responsibility moves to whoever runs the system.
Qwen3.6-35B-A3B shows the smaller-model version of the same trend:
Apache-2.0 licensing, 262,144 native context tokens, MCP examples, and agentic
coding numbers including 73.4 on SWE-bench Verified, 51.5 on Terminal-Bench 2.0,
and 37.0 on MCPMark. Not every loop needs the biggest model. Smaller systems can
still classify, route, retry, and prepare work for a stronger model or a human.
The chain is simple: strong tool use, downloadable models, cheaper local
serving, removable refusals, and persistence.
System
What is public
Source
GPT-5.5 VulnLMP
Multi-day vulnerability research campaigns, reproduced crashes, proof-of-concept inputs, and root-cause analysis; no verifier-confirmed Critical full-chain outcome in that evaluation.
Open-weight model with 1M context. Z.AI reports 81.0 on Terminal-Bench 2.1 versus 85.0 for Claude Opus 4.8, 76.8 on MCP-Atlas versus 77.8 for Opus 4.8, and API pricing of $1.4/$4.4 per million input/output tokens.
Apache-2.0 model card documents 262,144 native context tokens, MCP examples, 73.4 on SWE-bench Verified, 51.5 on Terminal-Bench 2.0, and 37.0 on MCPMark.
Heretic matters because it targets the safety behavior that makes a model say
no. If that layer is removed, do not expect the local model to stop the goal for
you. It can keep following goals that a hosted assistant would refuse.
Heretic is a public GitHub project, created on September 21, 2025, for removing
censorship or safety alignment from transformer language models without
expensive post-training. It describes automatic refusal removal and searches for
changes that reduce refusals while keeping the model close to its original
behavior. When I checked it on June 21, 2026, it showed about 25,000 GitHub
stars.
Now combine that with strong open-weight models such as GLM-5.2. A person can
run the model locally, add tools, retrieval, MCP connectors, instruction files,
and logs, and give it a goal. In that setup, “the model will probably say no” is
not a serious control.
That is why a local agent surface is risky. The model is no longer only
answering text. It can sit in a loop with code tools, an isolation setting, and
a goal field, then ask tools to act.
Heretic does not have to teach a model security from zero. Strong general
models already know a lot about code, Linux, networks, logs, and debugging. If
context is missing, the person running it can add it: documentation, AGENTS.md
files, search, vector databases, MCP tool connectors, tool output, and results
from earlier tries.
That is why the loop matters. The model brings general skill. The environment
adds local knowledge and tools. Each run adds fresh results. Together, that can
be enough for persistent security work.
Heretic weakens a model safety block at the same time that open-weight agent
models are getting stronger and cheaper. The risk is not one jailbreak
screenshot. The risk is a repeatable workflow with fewer stops: a goal, tools,
context, checks, and enough retries to keep going after the first failed
attempt.
Govern The Runtime
The runtime is the real control point. It decides what an agent can see, which
tools it can call, what it can change, and which credentials it can use.
Start with what outsiders can reach. Cheap agents can keep trying against public
apps, APIs, VPNs, admin panels, SaaS entry points, old subdomains, and partner
portals. Make that loop costly again: know your assets, patch them, require
MFA, rate-limit APIs, detect bots, log attempts, and keep exposed systems
separated from valuable internal systems.
Then limit your own agents. A helpful agent may ask for more access to finish a
task: install a tool, read a secret, open a network path, or change a
permission. That may be fine in a lab. In production it needs a hard boundary.
Keep the control set small and real:
permissions only for the task
short-lived credentials
separate workspaces
network allowlists
approval for risky actions
logs for every tool call
These controls live in the agent runner. Tools such as OpenHands can block
commands, ask for approval, log what happened, add trusted context, and turn on
tool connectors only when the task needs them.
Put policy where the work happens: commands, credentials, network access, tool
connectors, logs, tenants, and stop rules.
What The Evidence Proves
The evidence shows a simple chain.
Modern models can use tools well.
Some open-weight models are now close to hosted models such as ChatGPT and
Claude on important coding and tool benchmarks.
Safety blocks can be removed from a local model copy.
Local or rented GPU capacity can make repeated runs cheap.
That matters because many attacks do not need a perfect cyber expert. They need
a strong model, useful instructions, tools, test output, and many retries. The
agent loop does that repeated work: try, read the result, adjust, try again.
Defenders can use the same pattern in a controlled way. A company can run local,
sovereign AI on its own data, with its own logs, approvals, and small
permissions. The useful lesson is simple: govern the loop before an attacker
runs it without your rules.
Do Not Panic
Panic makes teams move fast in the wrong direction. They ban the visible tool,
buy another dashboard, or write broad policy while the real exposure stays
unchanged.
The better response is basic engineering. Know what is exposed. Patch old
systems. Rate-limit noisy paths. Separate tenants. Use short-lived credentials.
Log tool calls. If one app or one agent run goes wrong, isolate it fast and
stop it before the damage spreads.
Do not rely only on the model saying no. Heretic shows those safety blocks can
be removed from an open-weight model running locally. GLM-5.2 shows that strong
open models can run useful tool workflows on servers the operator controls.
Agents then repeat the workflow.
Put controls around action. Scope the goal. Keep permissions small. Limit the
blast radius. Verify results outside the model. Let humans approve real risk,
not rubber-stamp a run at the end.
Partially AI-modified / AI transparency: This publication is AI-assisted and human-reviewed. Constantin Korte assumes editorial responsibility. See AI Transparency.