Partially AI-modified / AI transparency: This publication is AI-assisted and human-reviewed. Constantin Korte assumes editorial responsibility. See AI Transparency.
Agentic on-prem AI is now cheap enough to matter for persistent attacks. Open weights lower the barrier, tools create the loop, and removed safety brakes turn strong models into practical attack engines.
Douglas Adams gave the Guide the right warning label: “Time is an illusion.
Lunchtime doubly so.”
In security, cheap retries are the uncomfortable punchline: a machine can keep
trying long after a human would have stopped.
Early LLM safety relied on friction: model refusals, API blocks, rate limits,
logging, reviews, account trust, and a chat window that mostly returned text. A
human still had to turn the answer into commands, context, and follow-through.
Practically, the shift is simple: agents connect models to tools, files,
browsers, terminals, repositories, and credentials. Open-weight models such as
GLM-5.2 are reaching frontier-class tool benchmarks. Heretic is a public project
for removing or weakening refusal behavior in transformer models. The short
version: the “no” can be removed after a model is published. If the model no
longer refuses the task, the real question is how far the agent can get before
a person stops the run.
Security often changes when repetition gets cheap. Reconnaissance,
categorization, validation, and pentest-style follow-through now take less
manual effort to repeat. Attackers do not all become experts overnight. More
people can run more attempts, against more targets, with fewer manual steps.
Some attempts will reach systems that were skipped because manual follow-through
was too expensive.
Three public signals point in the same direction. Anthropic’s Mythos Preview
shows specialized cyber capability jumping above Opus 4.6 on cyber benchmarks.
Z.AI reports GLM-5.2 close to Opus 4.8 on selected terminal and tool benchmarks,
and ahead of GPT-5.5 on at least one long-horizon benchmark in its own report.
Heretic showed about 25,000 GitHub stars when I checked it on June 21, 2026.
Together, they suggest stronger loops, cheaper runs, and refusal barriers that
are easier to remove.
The practical control point is the whole run: where it executes, which identity
it uses, which data it can read, which tools it can call, and what evidence
proves it should stop.
From Chat To Work Loop
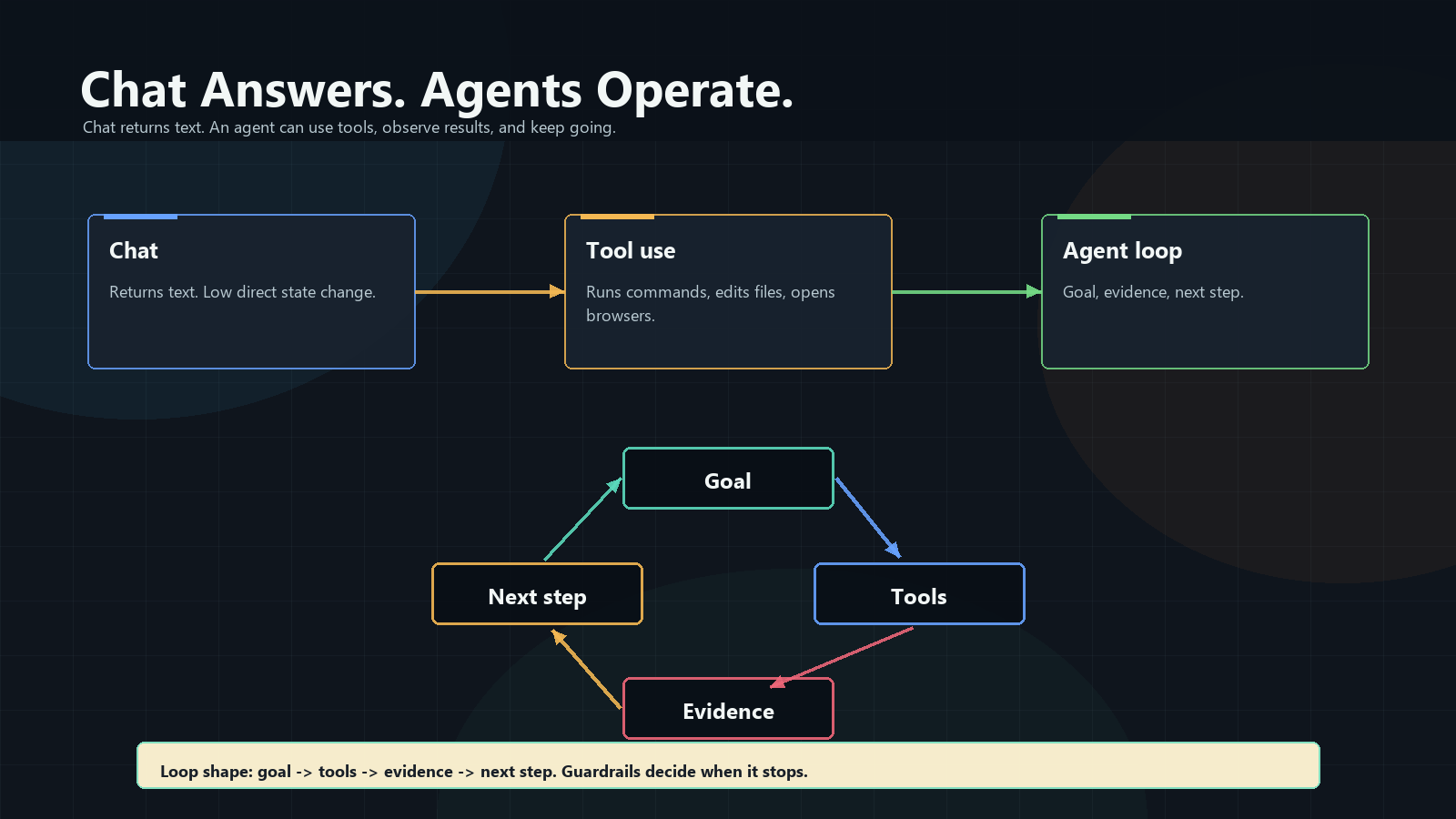
By “chat” I mean a normal LLM chat such as ChatGPT or Claude in a browser. The
model returns text, then waits. The person copies commands, checks output,
chooses the next step, retries, and remembers what failed.
An agent moves part of that work into software. It can keep a goal, call tools,
read files, run commands, open a browser, inspect output, and continue. A failed
step becomes the next input, not the end of the conversation.
Four terms matter:
- A chat response is content.
- A tool call is action.
- An agent run is a work loop with permissions.
- A goal adds a stop condition.
The product name matters less than the software around the model. Codex,
OpenHands, Claude Code, and similar tools give the model a workspace: files, a
shell, a browser, a repository, logs, and approval buttons. The model writes
text. The workspace decides whether that text can read a secret, run a command,
or change a system.
Plain terms help because the risk starts when text gains a path to action.
| Term | Plain meaning | What changes in the run |
|---|---|---|
| Runtime or harness | The controlled workspace around the model. | It decides permissions, logs, tools, approvals, and stop rules. |
| Tool call | The agent requests an action from the runtime: read a file, run a command, open a browser, call an API. | Text becomes action at this point. |
| MCP | A standard way to connect an agent to external tool servers. | It can expose approved tools to the run, but it also expands what the run can touch. |
| AGENTS.md or instruction file | A project note that tells the agent how to work in a specific repo or environment. | It can add local rules and knowledge the base model did not know before the run. |
| Retrieval or vector database | A search layer that feeds relevant documents or prior knowledge into the agent. | It can add knowledge the base model did not already carry, so source quality and access control become part of the risk. |
| Context window | The working memory the model can process at once, measured in tokens. | Long runs may compress, retrieve, or forget details; evidence should not depend on memory alone. |
| Blast radius | The maximum damage or data exposure one run can cause. | Smaller blast radius means one bad run is easier to contain. |
Where The Agent Runs Matters

The same model can be low risk in one place and dangerous in another. A cloud
run may stay inside a vendor sandbox. A local run may touch a developer laptop,
WSL, a lab network, or an internal admin machine. A managed runtime sits between
those cases, with scoped credentials, network rules, logs, and review gates.
Location sets the blast radius: which identities, files, secrets, networks, and
business systems the run can reach. Once text can become action, the next
question is where that action lands.
The operating check is simple:
- Which agent runs where?
- Which identity does it use?
- Which data and tools can it touch?
- Which logs, approvals, and stop rules govern the run?
Prompt Versus Goal
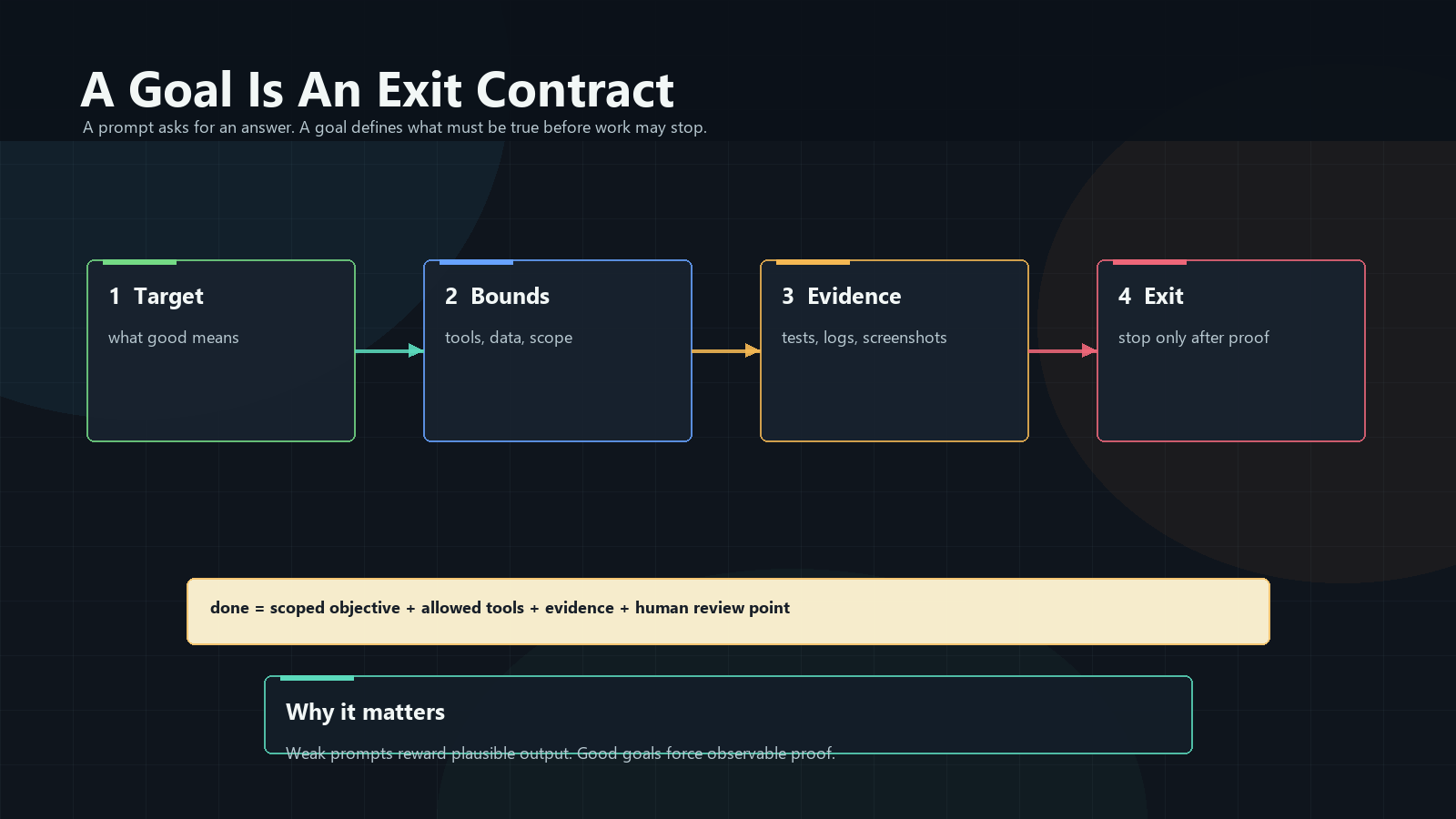
“Write Pong in Go” is a prompt.
“Write Pong in Go, create a test suite, measure memory and performance, prove it
can run smoothly, collect screenshots, and reconcile any failure before
stopping” is a goal.
The second version changes the job. It gives the agent a finish line, a way to
judge progress, and a reason to keep going after the first imperfect answer.
A goal turns output into follow-through. The agent can try, inspect, fix,
measure, and continue until the proof is good enough or a limit is reached. The
same pattern applies outside software: HR, finance, operations, and security all
need goals with limits and proof, not just clever text.
A goal should name:
- the target outcome
- the allowed tools
- the forbidden actions
- the data and systems in scope
- the evidence required before “done”
- the budget or time limit
- the human review point
That structure matters for security. A weaker model inside a strong loop can
beat a stronger model used once and abandoned. Persistence turns rough answers
into work, and work is what defenders must control.
The Safety Barriers Are Easier To Remove
Safety barriers are the friction that made early LLM misuse awkward: model
refusals, system prompts, API policy checks, monitoring, rate limits, account
trust, product UX, and a normal chat product that mostly returned text.
Early LLMs were safer partly because misuse was clumsy. A model could suggest a
direction, but a human still had to turn the answer into commands, install
tools, debug errors, keep context, and decide the next step. Most use was
tinkering, not continuous operation.
Agents remove much of that friction. The same model can now sit inside a loop
with a browser, shell, repository, file system, MCP tools, credentials, logs,
and a goal. It can try something, read the result, adjust, and try again. The
important change is cheaper follow-through.
Heretic targets another layer: refusal behavior. It does not give the model
secret cyber knowledge by itself. Knowledge can still come from retrieval,
AGENTS.md files, tool output, MCP servers, documentation, or a vector database.
Heretic matters because it makes one visible safety brake easier to remove while
open-weight models are becoming strong enough for serious tool work.
The main story is the combination: loops, Heretic-style refusal removal, and
frontier-class open models. A malicious agent no longer needs to live behind a
major hosted provider. It can run locally or in someone else’s cloud account,
with private tools and private knowledge attached. Many runs will still fail.
The entry barrier is lower anyway.
Recent evidence supports that concern. OpenAI describes GPT-5.5 running
multi-day vulnerability-research campaigns in VulnLMP. Anthropic reported
Mythos Preview beating Opus 4.6 on CyberGym and Terminal-Bench. Z.AI reports
GLM-5.2 close to Opus 4.8 on selected terminal and MCP benchmarks. The tests
differ, but the operational concern is plain: capable models can already do
serious multi-step tool work. Put that capability inside a loosely governed
agent harness, and chat-era refusals are no longer enough.
The Economics Are The Warning
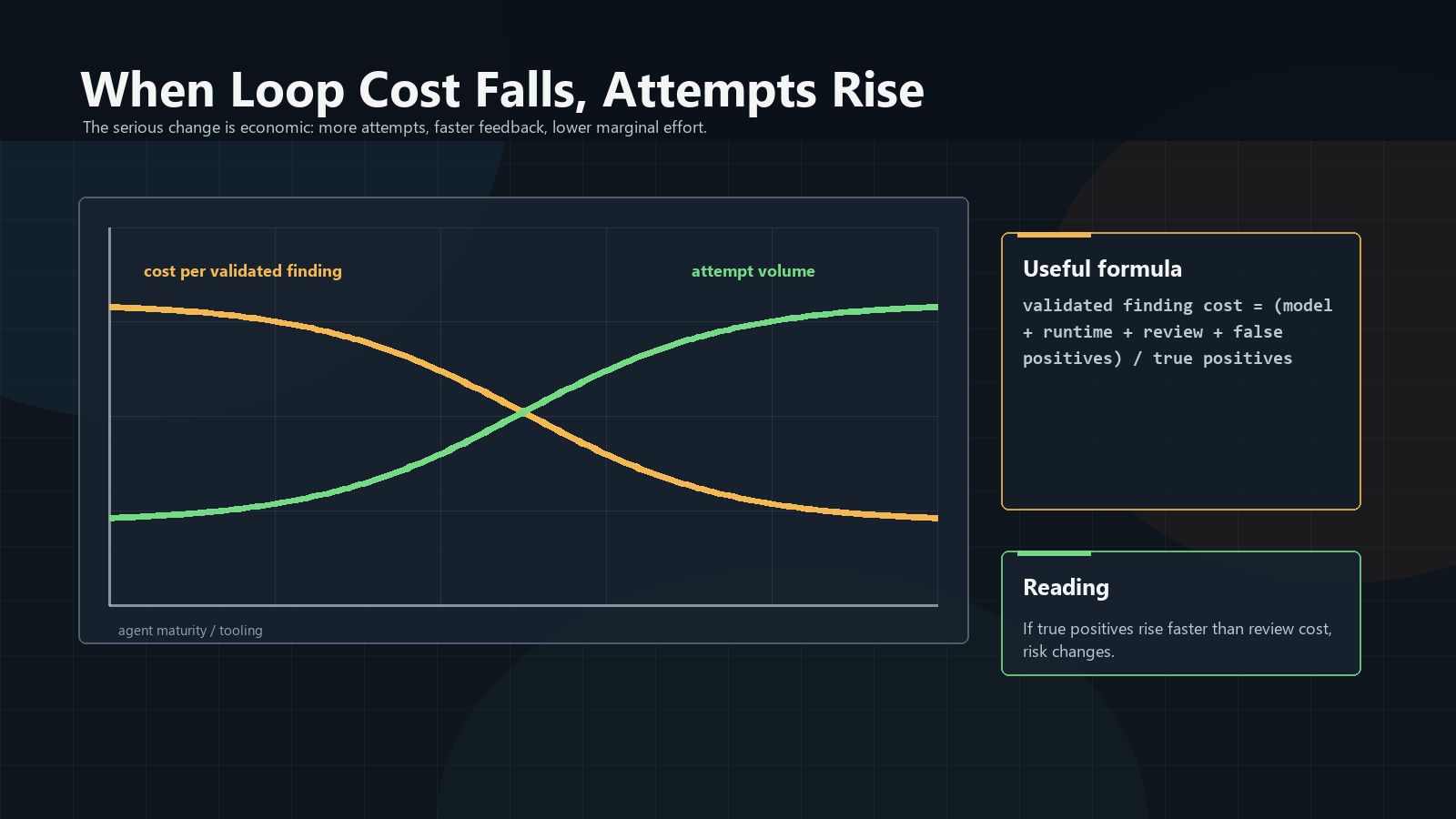
Track the cost per validated finding. Count model cost, runtime, sandboxing,
tools, human review, and false positives. Divide that by the number of true
positives.
Cheaper follow-through means more attempts. If true positives rise faster than
review cost, staffing and review budgets change.
Bad agents still waste money. Good harnesses still produce false positives.
Local models may be weaker than hosted frontier models. Hosted models may have
better monitoring and abuse controls than a random local setup. No setup wins
across every workload.
Plan for more actors running more attempts against more targets for less
marginal effort. Some attempts will be noisy. Some will be wrong. Some will find
the thing nobody has looked at in two years.
Persistence Changes The Distribution

The main risk is not smarter attackers. The main risk is cheaper repetition.
Many cyber tasks are normal IT work repeated many times: read code, read logs,
check dependencies, read command output, sort findings, and decide the next
step. A general model already has many of those skills: programming, Linux,
networking, debugging, and language.
Extra security knowledge can be added later through documentation, search,
retrieved notes, AGENTS.md files, MCP tool servers, scan output, and results
from earlier runs. MCP just means a standard way to connect an agent to tools.
The chart says one simple thing: when one attempt gets cheaper, more attempts
happen. More attempts means more old VPNs, forgotten admin panels, stale
dependencies, exposed backups, and internal tools get checked.

The public evidence is already strong enough to plan for. Anthropic’s Project
Glasswing shows what a special cyber model can do: Mythos Preview scored 83.1%
on CyberGym versus 66.6% for Opus 4.6. Glasswing partners also reported more
than 10,000 high- or critical-severity findings.
OpenAI’s GPT-5.5 VulnLMP result shows the same pattern with a top hosted model
and tools. It ran multi-day vulnerability research, reproduced crashes, and
wrote root-cause analysis. It did not prove a fully automatic critical exploit
chain in that test. It still shows that long tool runs already matter.
Availability changed after that. Anthropic says a June 12, 2026 US
export-control directive forced it to disable Fable 5 and Mythos 5 for all
customers. So the Glasswing numbers are evidence from a limited preview window,
not a product someone can simply buy today.

The cyber-model lesson is simple: the bottleneck moves. First, the model finds
more issues. Then the hard work becomes checking which findings are real,
setting priority, disclosing responsibly, and patching fast enough.
| Public signal | Reported detail | Source |
|---|---|---|
| Claude Mythos Preview | 83.1% on CyberGym vulnerability reproduction, versus 66.6% for Opus 4.6. | Project Glasswing |
| Claude Mythos Preview | 82.0% on Terminal-Bench 2.0, versus 65.4% for Opus 4.6. | Project Glasswing |
| Claude Mythos Preview | 93.9% on SWE-bench Verified, versus 80.8% for Opus 4.6. | Project Glasswing |
| Project Glasswing | Roughly 50 initial partners, more than 10,000 high- or critical-severity findings, and about 150 added organizations. | Expanding Project Glasswing |
| Project Glasswing pricing | Preview pricing after credits: $25 per million input tokens and $125 per million output tokens. | Project Glasswing |
| Fable/Mythos access | Anthropic says a June 12, 2026 US export-control directive forced it to disable Fable 5 and Mythos 5 for all customers. | Anthropic access statement |

Open-weight models change who can run this kind of work. “Open-weight” means
the model can be downloaded and run outside the vendor’s hosted service.
GLM-5.2 has a 1M-token context. In plain English: it can keep a lot of
instructions, logs, code, and notes in one run. On Z.AI’s own table it is close
to Claude Opus 4.8 on tool tests: 81.0 versus 85.0 on Terminal-Bench 2.1, and
76.8 versus 77.8 on MCP-Atlas. Z.AI also reports GLM-5.2 slightly ahead of
GPT-5.5 on one long-task benchmark.
The connection is direct. Mythos shows how strong agentic models can create a
flood of security findings. GLM-5.2 shows that open models are getting close to
top hosted models on tool work. Heretic-style refusal removal can remove or
weaken one safety brake. Put together, this creates a private model that can run
with tools and keep trying.
The cost is low enough to matter. A useful attack loop needs a model, a goal,
tools, memory, retries, and a way to check results. It does not need a special
cyber model for every step. If the loop is cheap enough, smaller malicious
groups can run many more attempts.
A high-level setup looks like this:
- one 8x B200/HGX-class GPU server
- 2-4TB system memory
- fast local storage
- software that runs a compressed open model such as GLM-5.2
- agent software that connects the model to tools, search, logs, and review
For defense, every part of that setup needs strict permissions and logging. For
misuse, the same setup can run with weaker safety and keep retrying.
The hardware is not small. GLM-5.2 is very large. In full precision, its weights
alone are about 1.5TB. In practice, operators compress the model and batch many
requests together. Unsloth puts 8-bit inference around 810GB of total RAM plus
GPU memory. An 8x B200 node has about 1.44TB of fast GPU memory, so it is in the
right hardware class. Public 8x HGX B200 listings are already in the low-$400k
range before support, networking, and rack work. A rough $400k-$600k server,
paid over three years and kept busy, lands around $20-$25 per hour after power
and cooling.
| Busy-node output throughput | Approx. node cost at $21/hour |
|---|---|
| 2,500 tokens/s | $2.33 per 1M generated tokens |
| 5,000 tokens/s | $1.17 per 1M generated tokens |
| Break-even vs Z.AI GLM-5.2 output API | about 1,326 tokens/s |
| Break-even vs GPT-5.5 output API | about 195 tokens/s |
| Break-even vs Mythos Preview output API | about 47 tokens/s |
These are not guaranteed speed numbers. Long context, compression, batching,
latency, and serving software all change the result. The important part is the
break-even line. Once a busy node produces about 1,326 generated tokens per
second, it is already cheaper than Z.AI’s public GLM-5.2 API output price. It
beats GPT-5.5 output pricing at roughly 195 tokens per second and Mythos Preview
pricing at roughly 47 tokens per second.
| Reference price | Public price point |
|---|---|
| Claude Mythos Preview | $25 per 1M input tokens, $125 per 1M output tokens after preview credits |
| OpenAI GPT-5.5 | $5 per 1M input tokens, $30 per 1M output tokens |
| OpenAI GPT-5.4 | $2.50 per 1M input tokens, $15 per 1M output tokens |
| Z.AI GLM-5.2 API | $1.4 per 1M input tokens, $4.4 per 1M output tokens |
| 8x B200 GLM-5.2 on-prem scenario | about $1-$2.50 per 1M generated tokens at 2,500-5,000 tokens/s, before staff and datacenter overhead |
A malicious group does not need Mythos access to run persistent attacks. It can
use open models with strong general tool skills, remove or weaken refusals, add
its own notes and tools, and spend GPU time instead of buying a hosted model
with the provider’s safety checks. The cost changed, and the safety
responsibility moves to whoever runs the system.
Qwen3.6-35B-A3B shows the smaller-model version of the same trend:
Apache-2.0 licensing, 262,144 native context tokens, MCP examples, and agentic
coding numbers including 73.4 on SWE-bench Verified, 51.5 on Terminal-Bench 2.0,
and 37.0 on MCPMark. Not every loop needs the biggest model. Smaller systems can
still classify, route, retry, and prepare work for a stronger model or a human.
The chain is simple: strong tool use, downloadable models, cheaper local
serving, removable refusals, and persistence.
| System | What is public | Source |
|---|---|---|
| GPT-5.5 VulnLMP | Multi-day vulnerability research campaigns, reproduced crashes, proof-of-concept inputs, and root-cause analysis; no verifier-confirmed Critical full-chain outcome in that evaluation. | OpenAI deployment safety |
| GLM-5.2 | Open-weight model with 1M context. Z.AI reports 81.0 on Terminal-Bench 2.1 versus 85.0 for Claude Opus 4.8, 76.8 on MCP-Atlas versus 77.8 for Opus 4.8, and API pricing of $1.4/$4.4 per million input/output tokens. | GLM-5.2 model card, Z.AI pricing |
| Qwen3.6-35B-A3B | Apache-2.0 model card documents 262,144 native context tokens, MCP examples, 73.4 on SWE-bench Verified, 51.5 on Terminal-Bench 2.0, and 37.0 on MCPMark. | Qwen3.6-35B-A3B |
Heretic Makes Refusals Editable
Heretic matters because it targets the safety behavior that makes a model say
no. If that layer is removed, do not expect the local model to stop the goal for
you. It can keep following goals that a hosted assistant would refuse.
Heretic is a public GitHub project, created on September 21, 2025, for removing
censorship or safety alignment from transformer language models without
expensive post-training. It describes automatic refusal removal and searches for
changes that reduce refusals while keeping the model close to its original
behavior. When I checked it on June 21, 2026, it showed about 25,000 GitHub
stars.
Now combine that with strong open-weight models such as GLM-5.2. A person can
run the model locally, add tools, retrieval, MCP connectors, instruction files,
and logs, and give it a goal. In that setup, “the model will probably say no” is
not a serious control.
That is why a local agent surface is risky. The model is no longer only
answering text. It can sit in a loop with code tools, an isolation setting, and
a goal field, then ask tools to act.
Heretic does not have to teach a model security from zero. Strong general
models already know a lot about code, Linux, networks, logs, and debugging. If
context is missing, the person running it can add it: documentation, AGENTS.md
files, search, vector databases, MCP tool connectors, tool output, and results
from earlier tries.
That is why the loop matters. The model brings general skill. The environment
adds local knowledge and tools. Each run adds fresh results. Together, that can
be enough for persistent security work.
Heretic weakens a model safety block at the same time that open-weight agent
models are getting stronger and cheaper. The risk is not one jailbreak
screenshot. The risk is a repeatable workflow with fewer stops: a goal, tools,
context, checks, and enough retries to keep going after the first failed
attempt.
Govern The Runtime
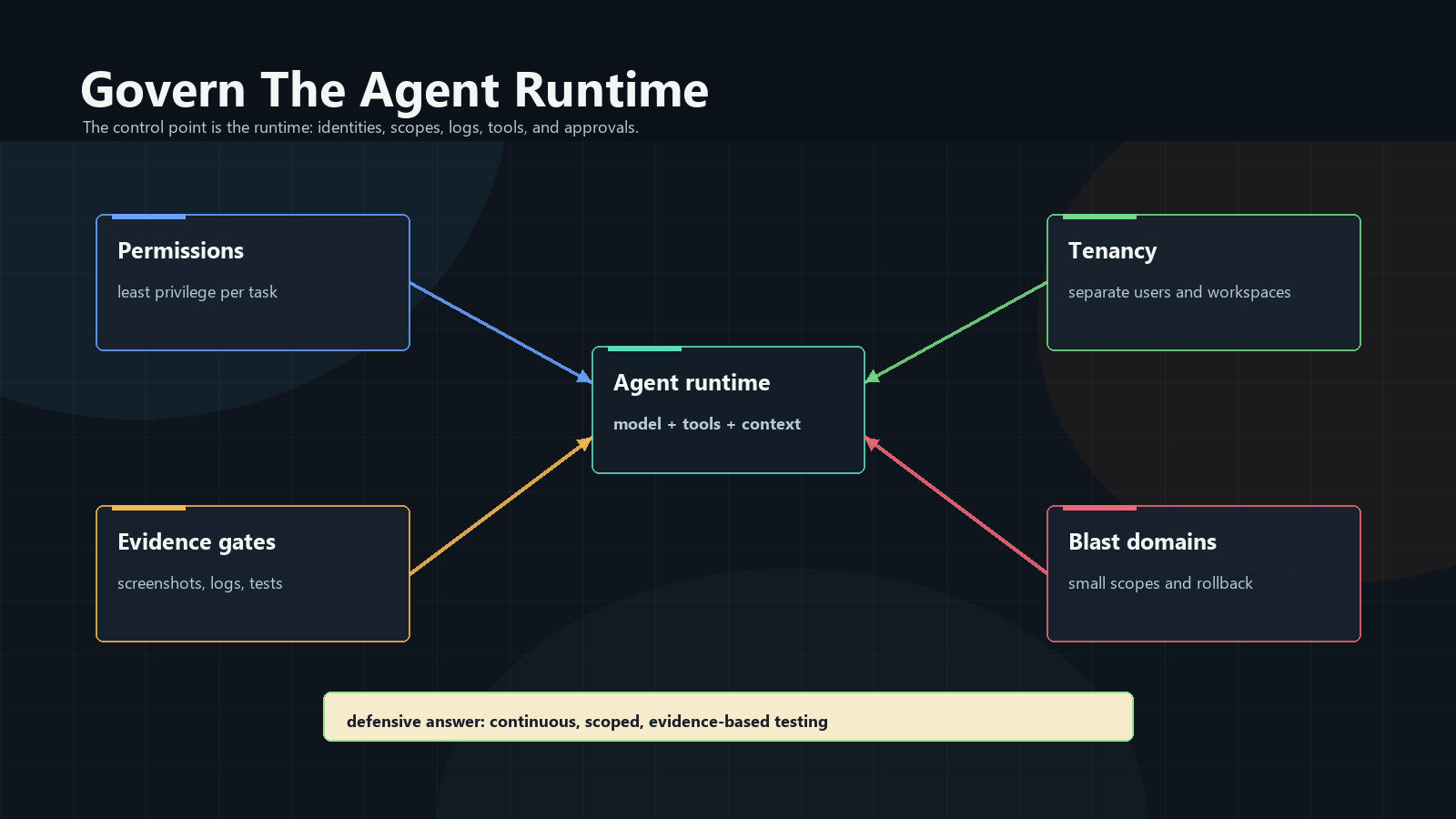
The runtime is the real control point. It decides what an agent can see, which
tools it can call, what it can change, and which credentials it can use.
Start with what outsiders can reach. Cheap agents can keep trying against public
apps, APIs, VPNs, admin panels, SaaS entry points, old subdomains, and partner
portals. Make that loop costly again: know your assets, patch them, require
MFA, rate-limit APIs, detect bots, log attempts, and keep exposed systems
separated from valuable internal systems.
Then limit your own agents. A helpful agent may ask for more access to finish a
task: install a tool, read a secret, open a network path, or change a
permission. That may be fine in a lab. In production it needs a hard boundary.
Keep the control set small and real:
- permissions only for the task
- short-lived credentials
- separate workspaces
- network allowlists
- approval for risky actions
- logs for every tool call
These controls live in the agent runner. Tools such as OpenHands can block
commands, ask for approval, log what happened, add trusted context, and turn on
tool connectors only when the task needs them.
Put policy where the work happens: commands, credentials, network access, tool
connectors, logs, tenants, and stop rules.
What The Evidence Proves
The evidence shows a simple chain.
- Modern models can use tools well.
- Some open-weight models are now close to hosted models such as ChatGPT and
Claude on important coding and tool benchmarks. - Safety blocks can be removed from a local model copy.
- Local or rented GPU capacity can make repeated runs cheap.
That matters because many attacks do not need a perfect cyber expert. They need
a strong model, useful instructions, tools, test output, and many retries. The
agent loop does that repeated work: try, read the result, adjust, try again.
Defenders can use the same pattern in a controlled way. A company can run local,
sovereign AI on its own data, with its own logs, approvals, and small
permissions. The useful lesson is simple: govern the loop before an attacker
runs it without your rules.
Do Not Panic
Panic makes teams move fast in the wrong direction. They ban the visible tool,
buy another dashboard, or write broad policy while the real exposure stays
unchanged.
The better response is basic engineering. Know what is exposed. Patch old
systems. Rate-limit noisy paths. Separate tenants. Use short-lived credentials.
Log tool calls. If one app or one agent run goes wrong, isolate it fast and
stop it before the damage spreads.
Do not rely only on the model saying no. Heretic shows those safety blocks can
be removed from an open-weight model running locally. GLM-5.2 shows that strong
open models can run useful tool workflows on servers the operator controls.
Agents then repeat the workflow.
Put controls around action. Scope the goal. Keep permissions small. Limit the
blast radius. Verify results outside the model. Let humans approve real risk,
not rubber-stamp a run at the end.
If a system can act, control what it can touch.
Sources Checked
Checked on June 21-22, 2026.
- OpenAI Codex CLI
- OpenAI Codex web
- OpenAI Codex prompting and goal mode
- OpenAI tokens help article
- Anthropic Project Glasswing
- Anthropic Expanding Project Glasswing
- Anthropic Project Glasswing initial update
- Anthropic Fable/Mythos access statement
- OpenAI GPT-5.5 VulnLMP deployment safety material
- GLM-5.2 long-horizon model post
- GLM-5.2 model card
- Z.AI pricing
- Unsloth GLM-5.2 local serving guide
- NVIDIA DGX B200
- Lenovo Press HGX B200 GPU specifications
- BIZON X9000 G4 8x HGX B200 listing
- OpenAI API pricing
- Qwen3.6-35B-A3B model page
- OpenHands hooks documentation
- OpenHands MCP documentation
- Heretic repository
- Douglas Adams quote reference